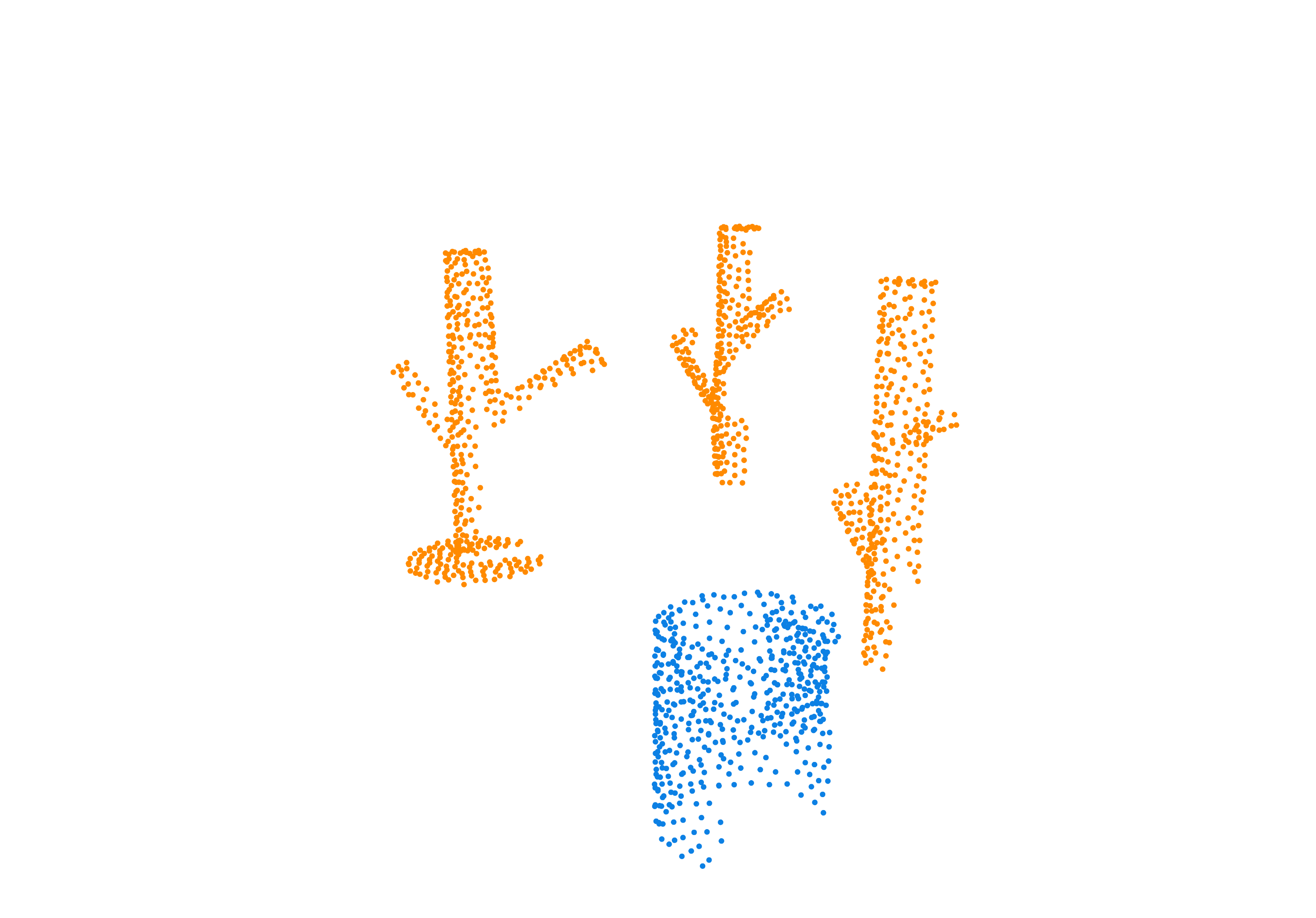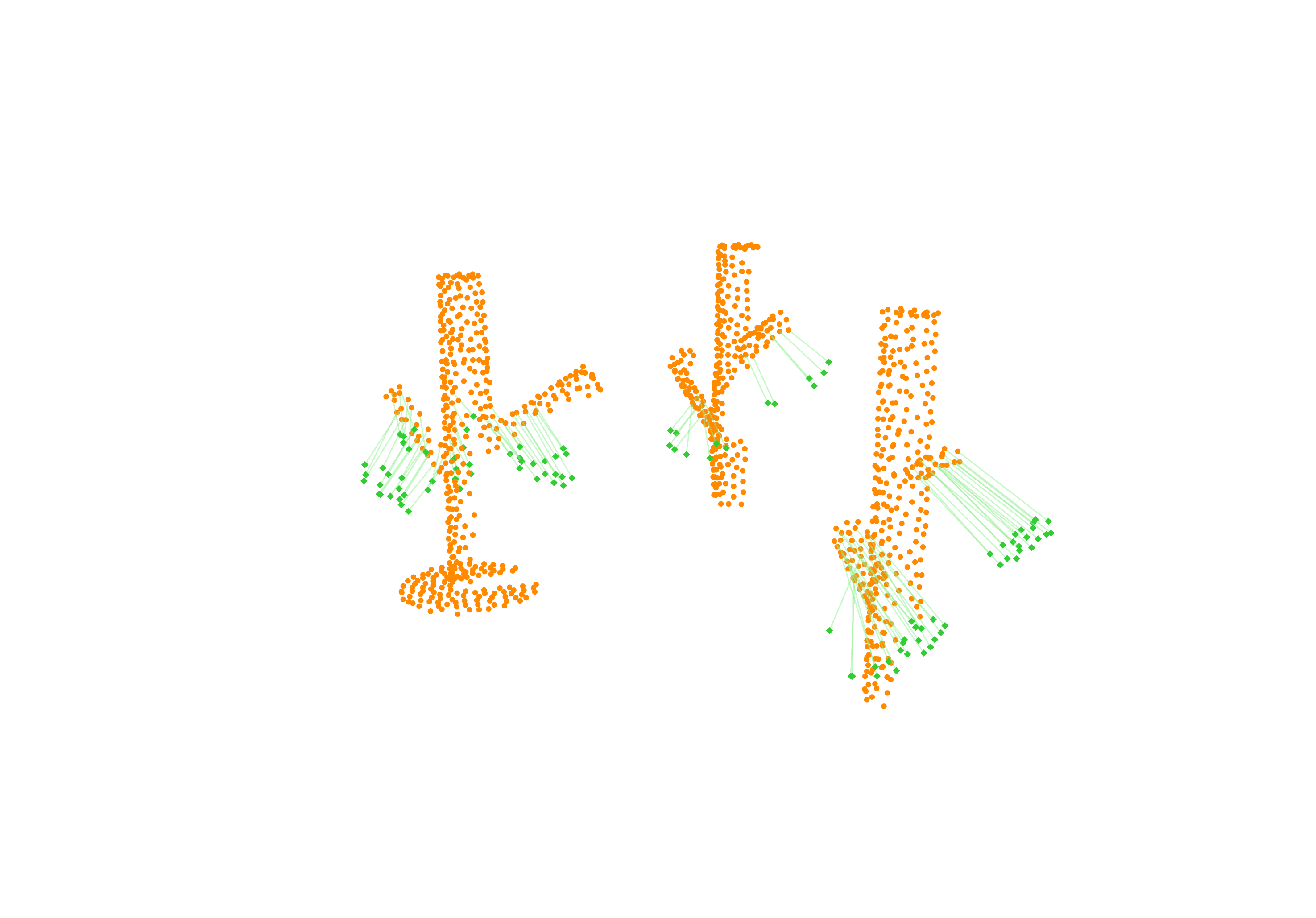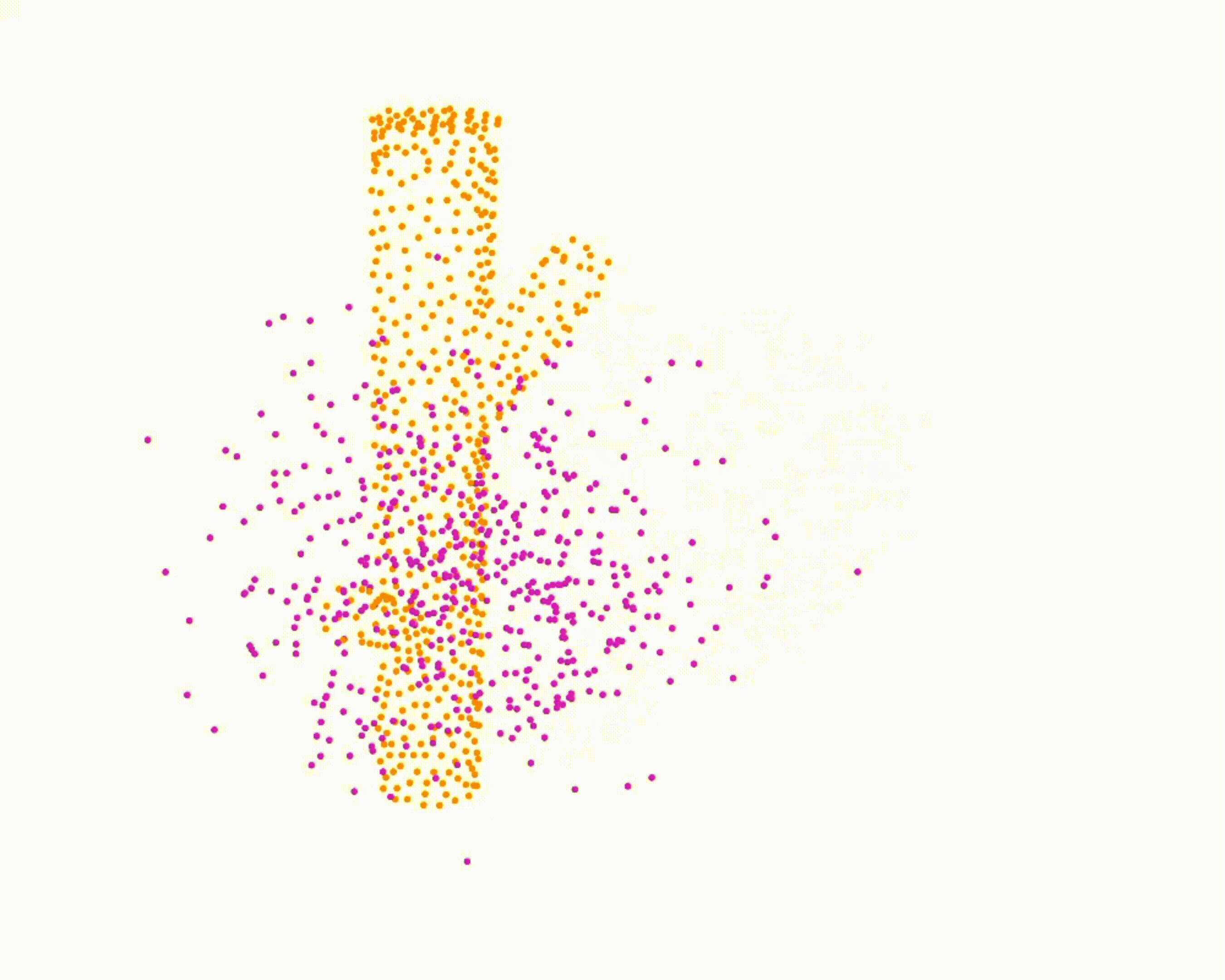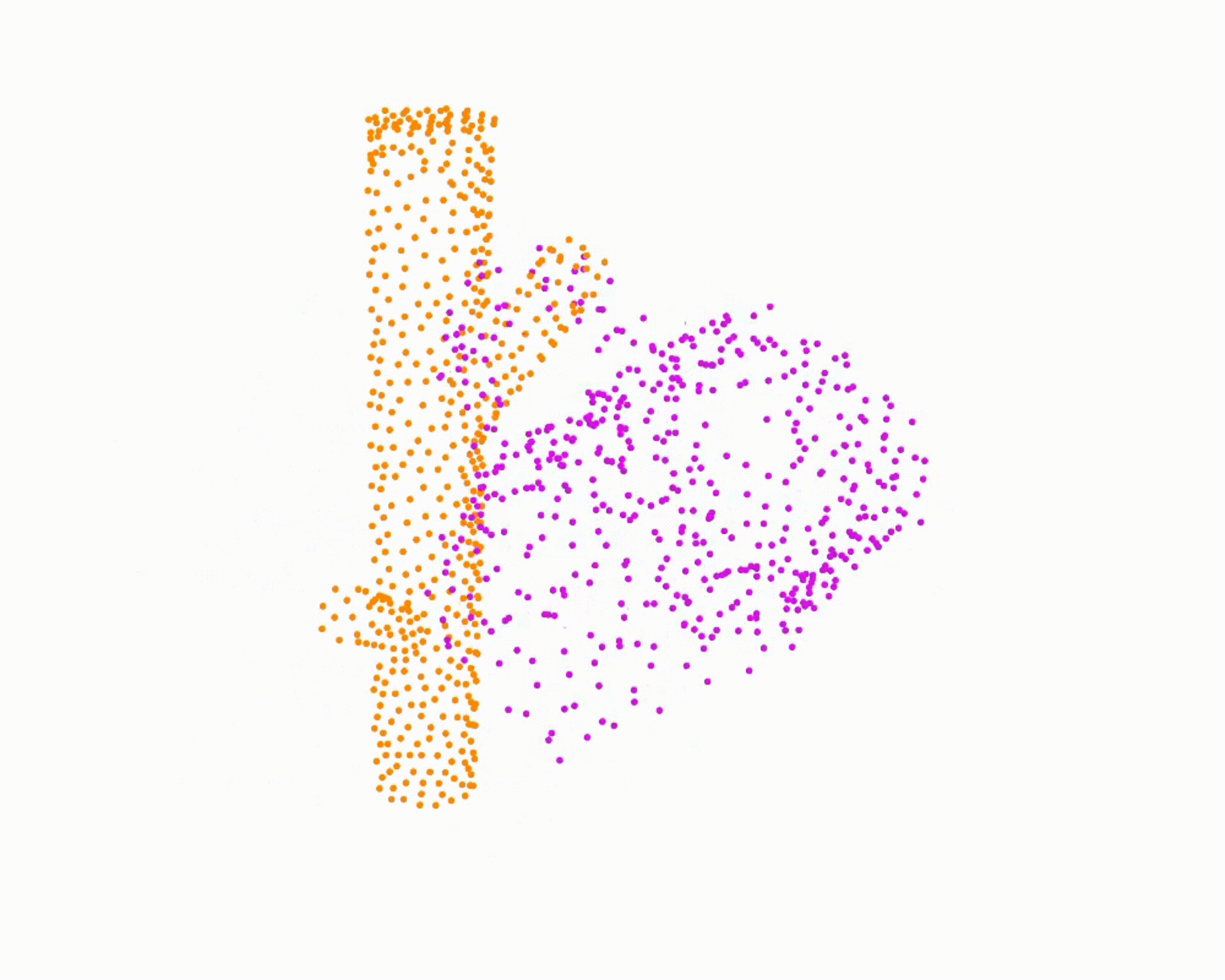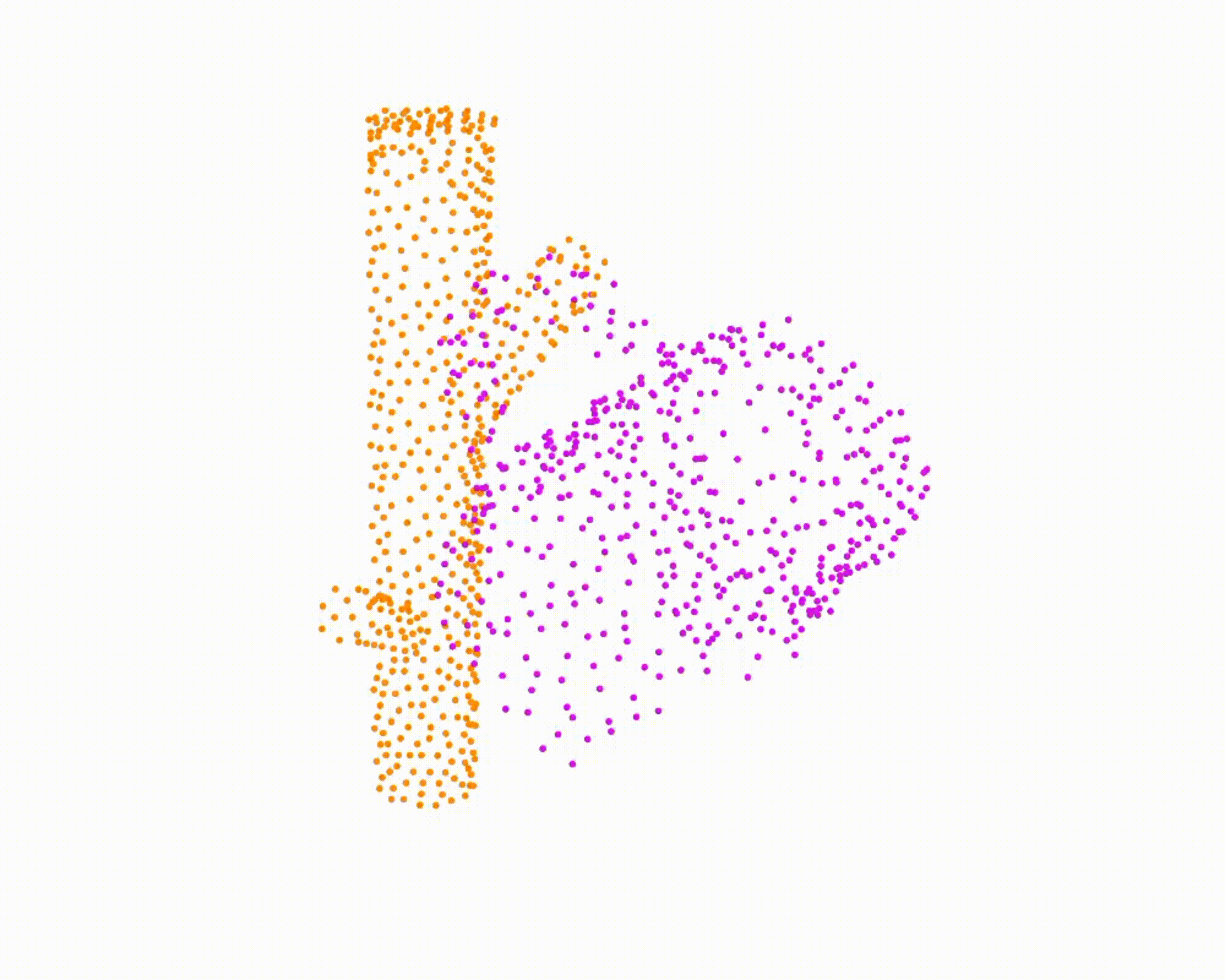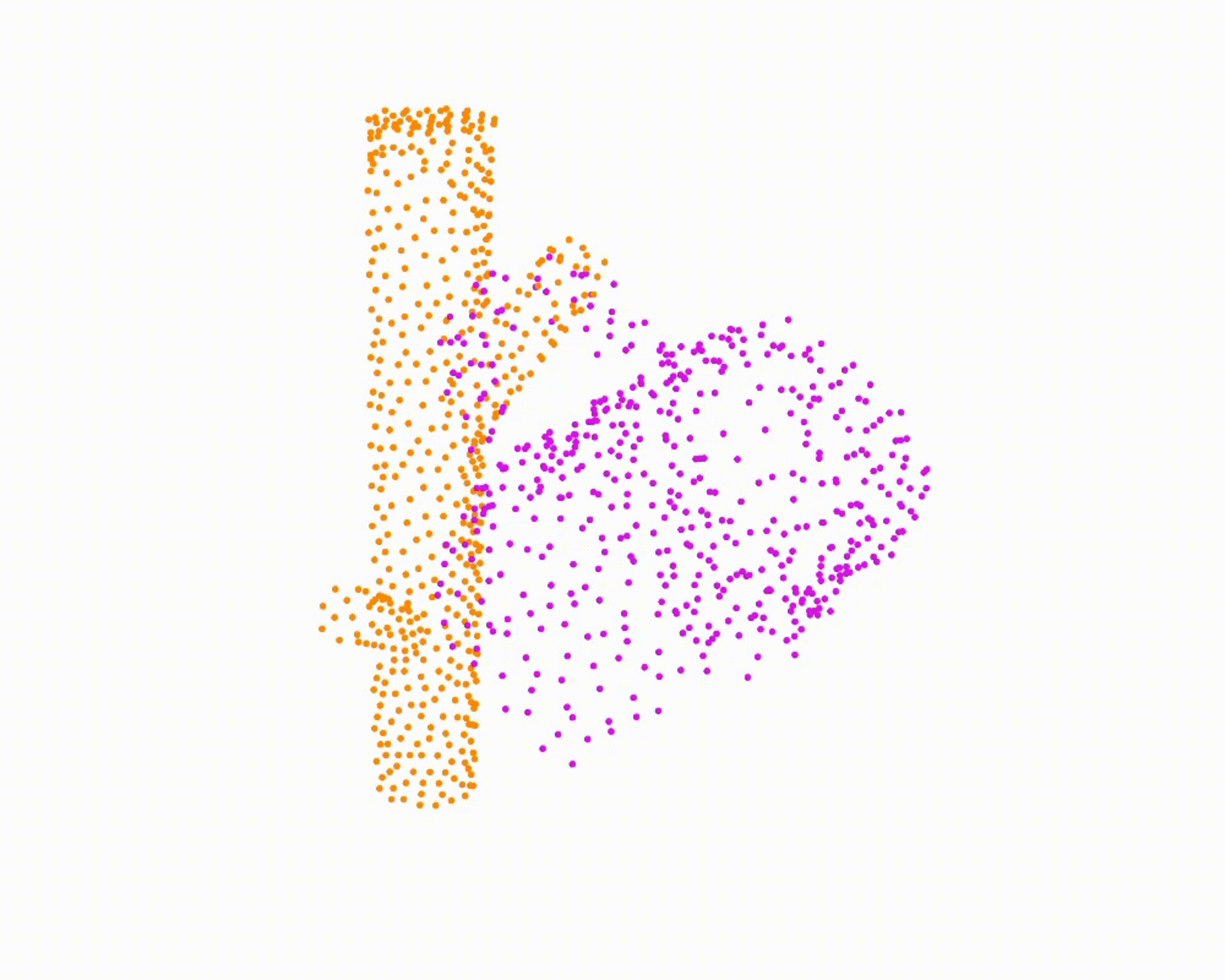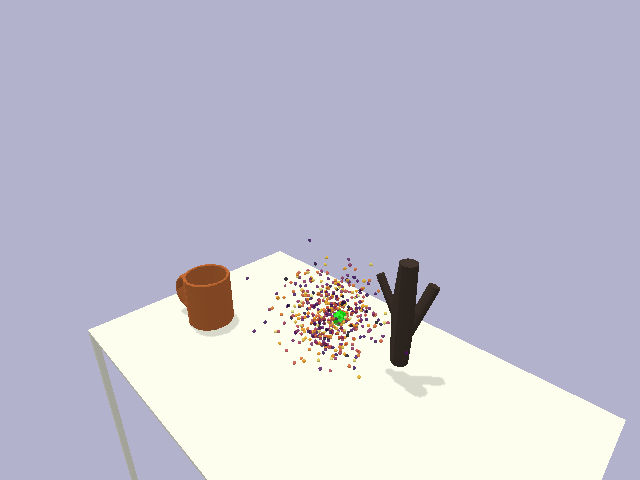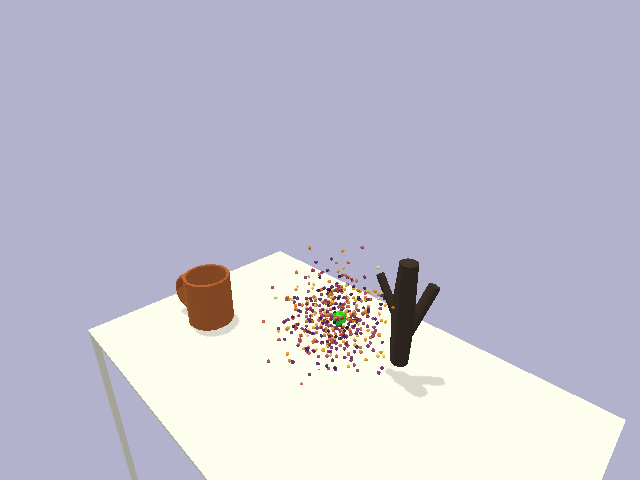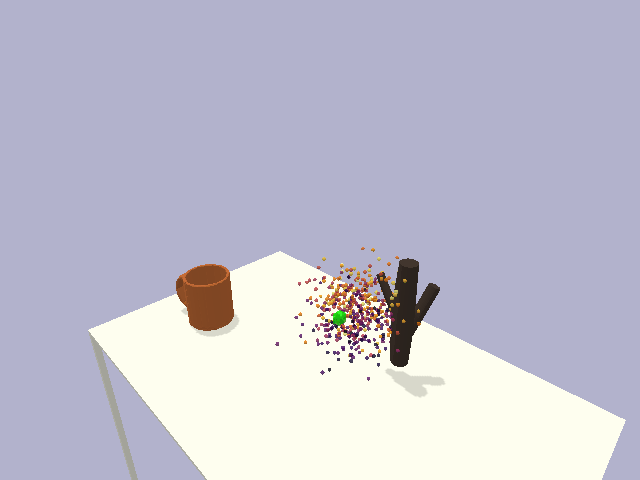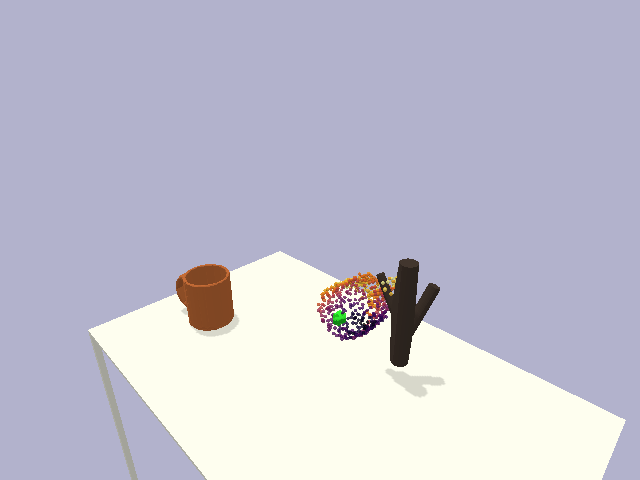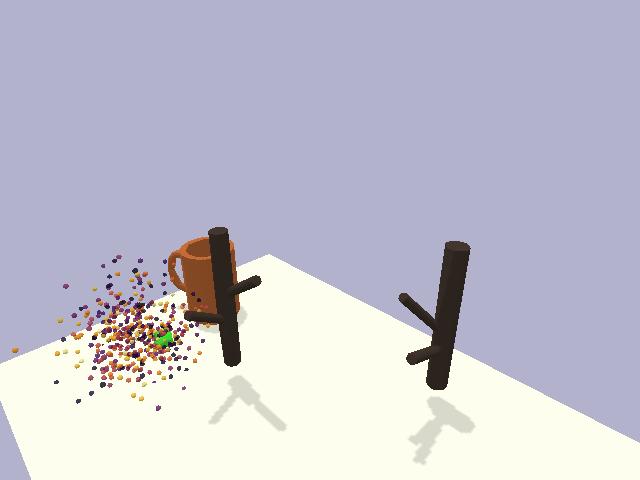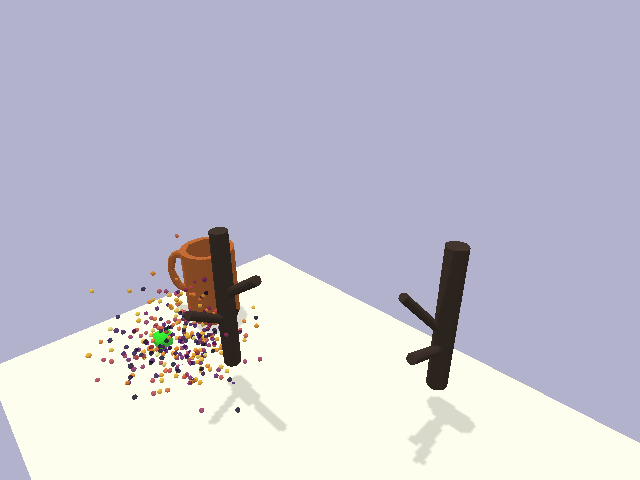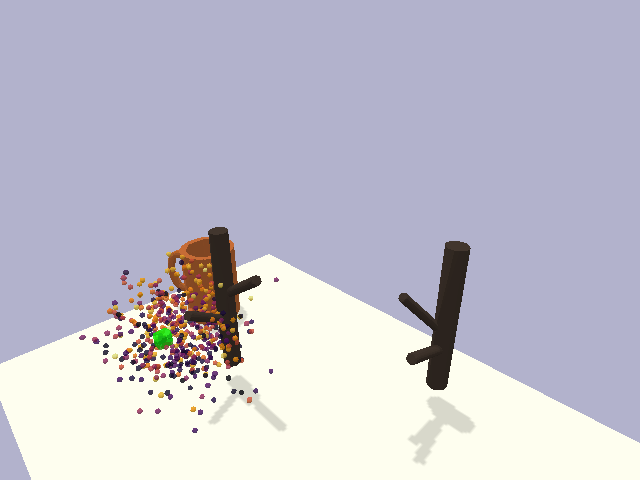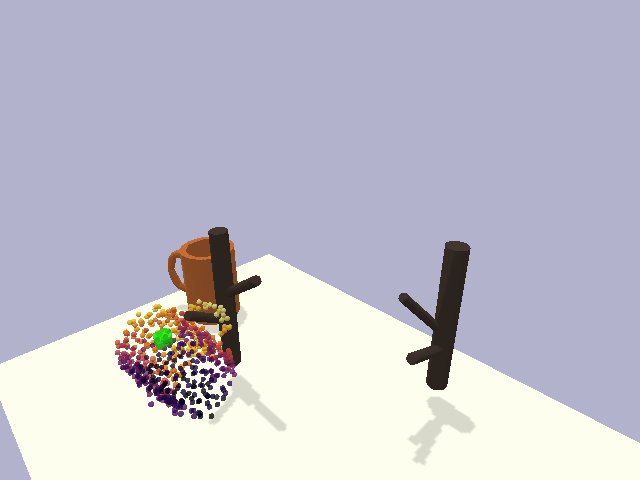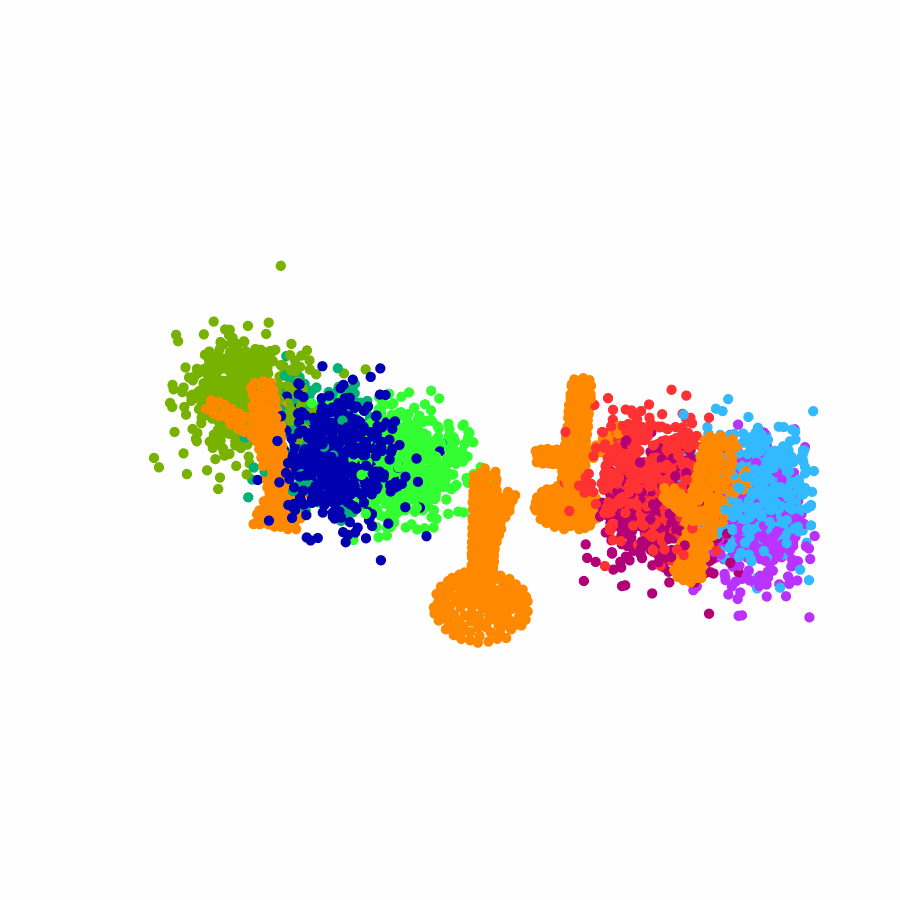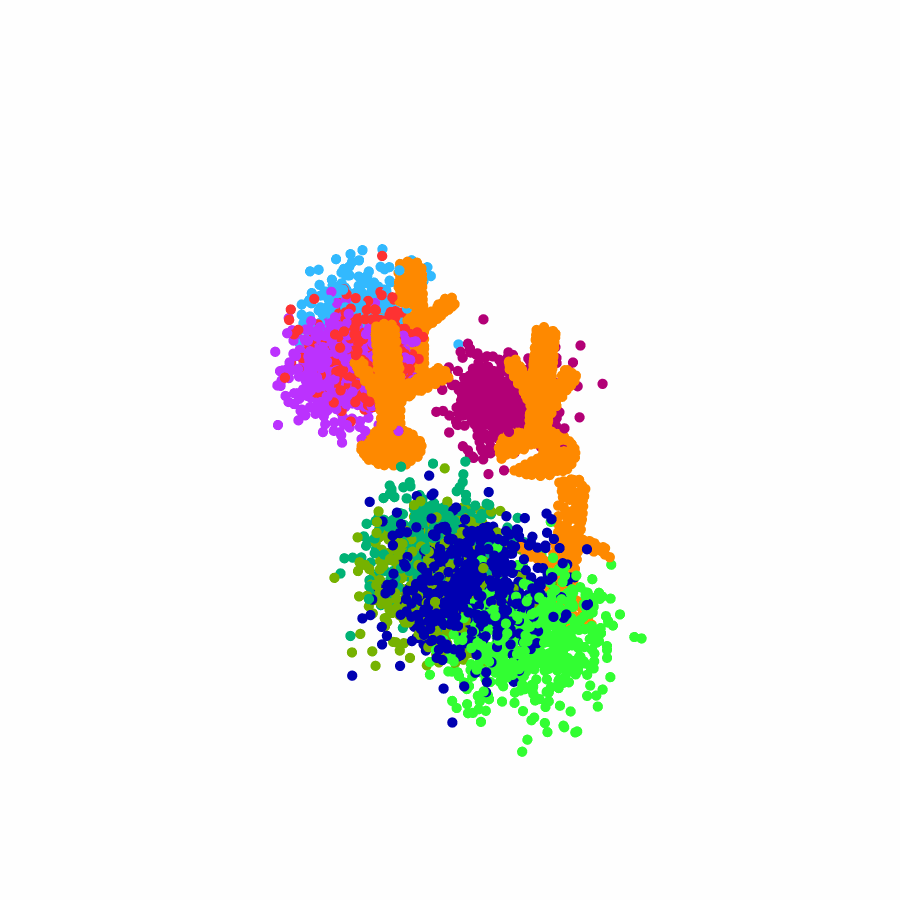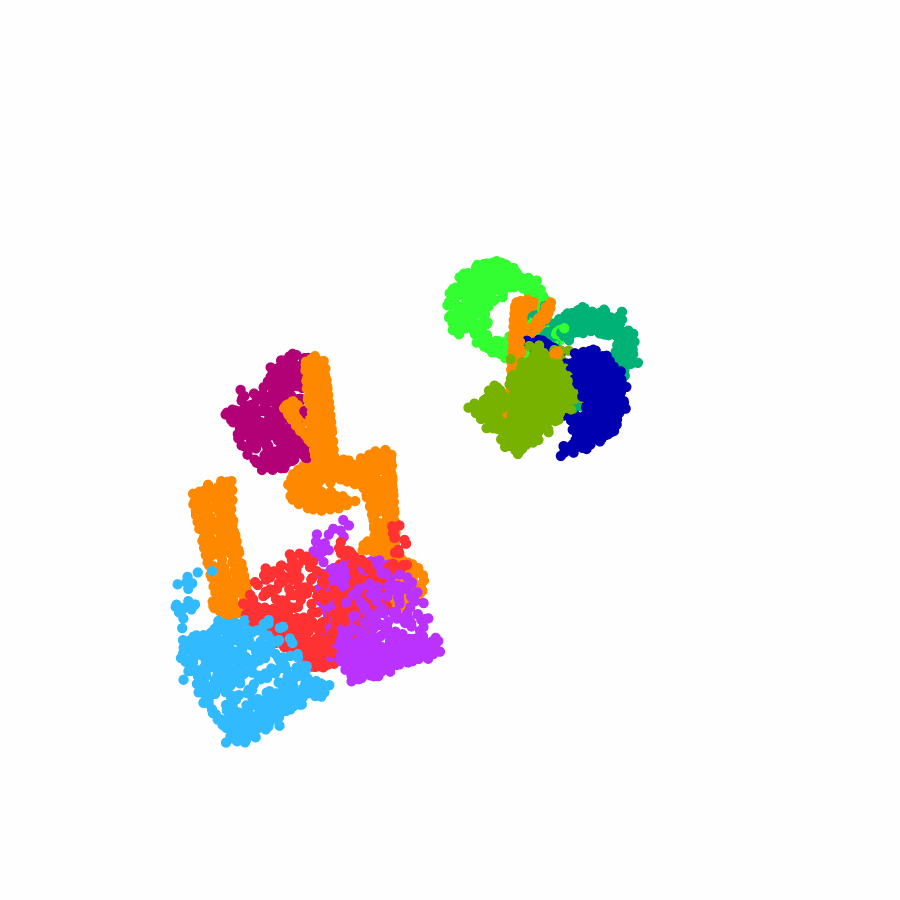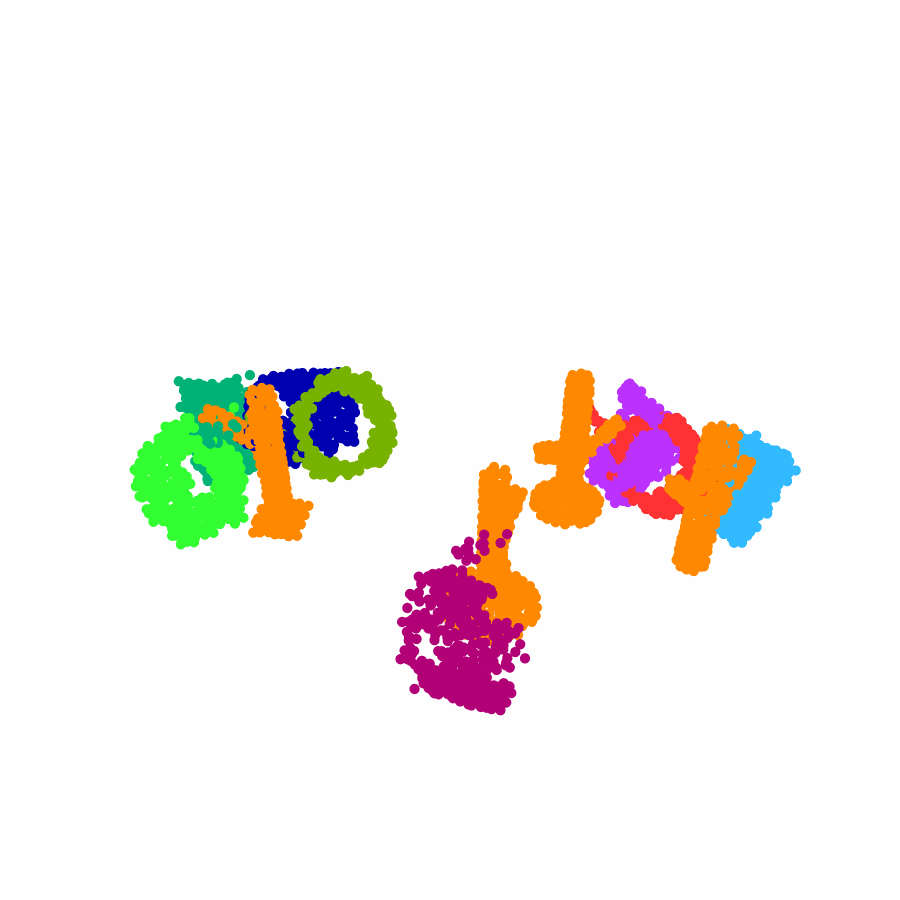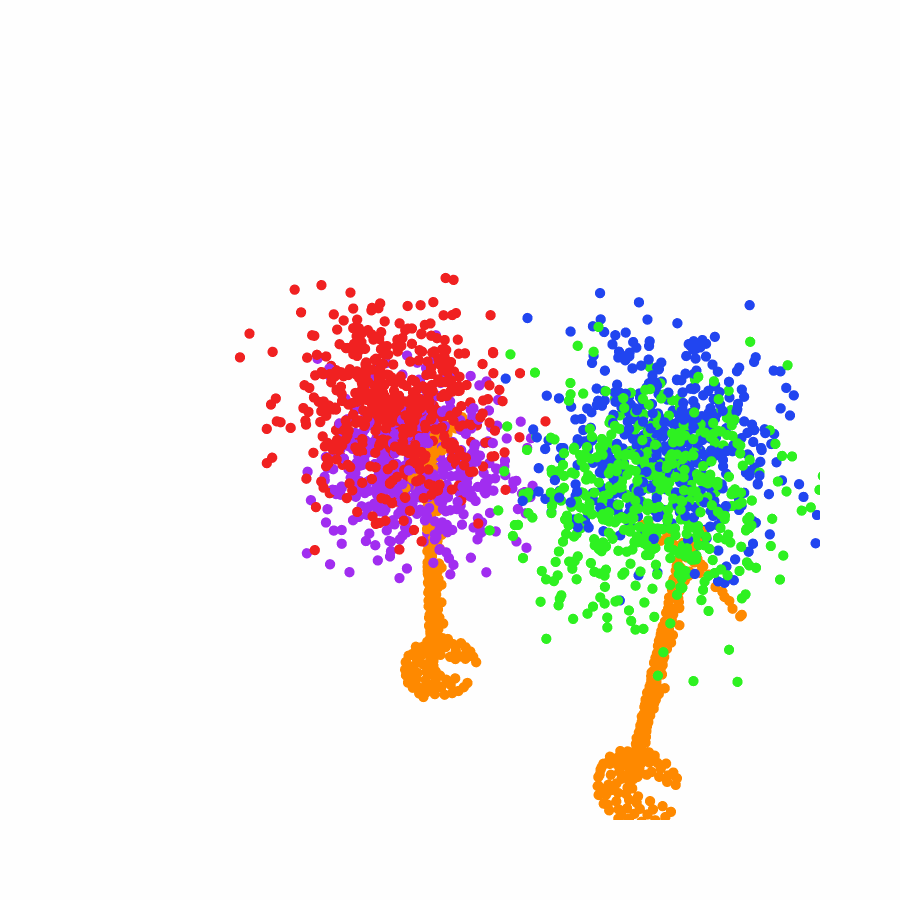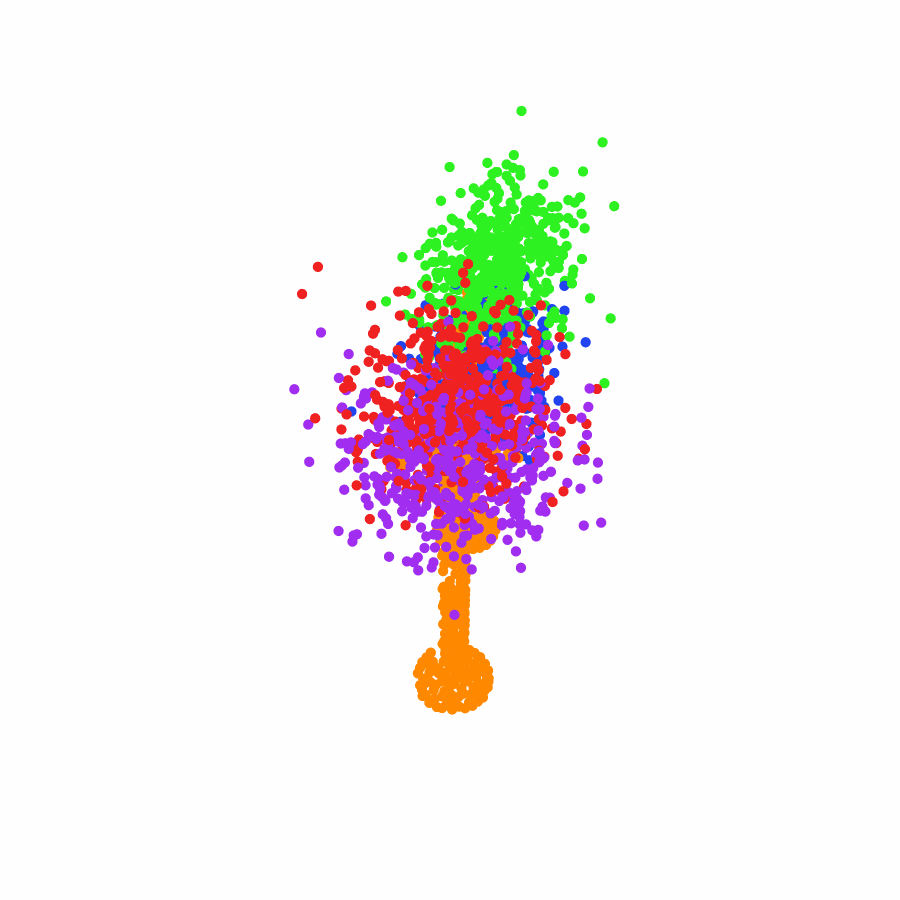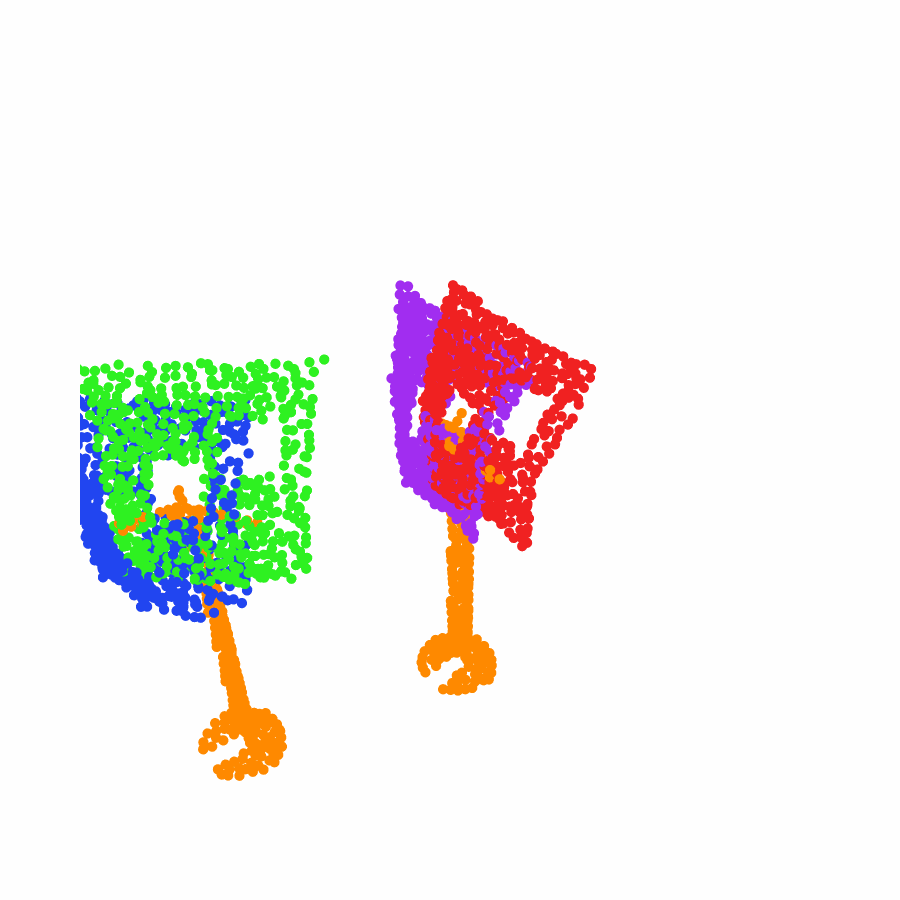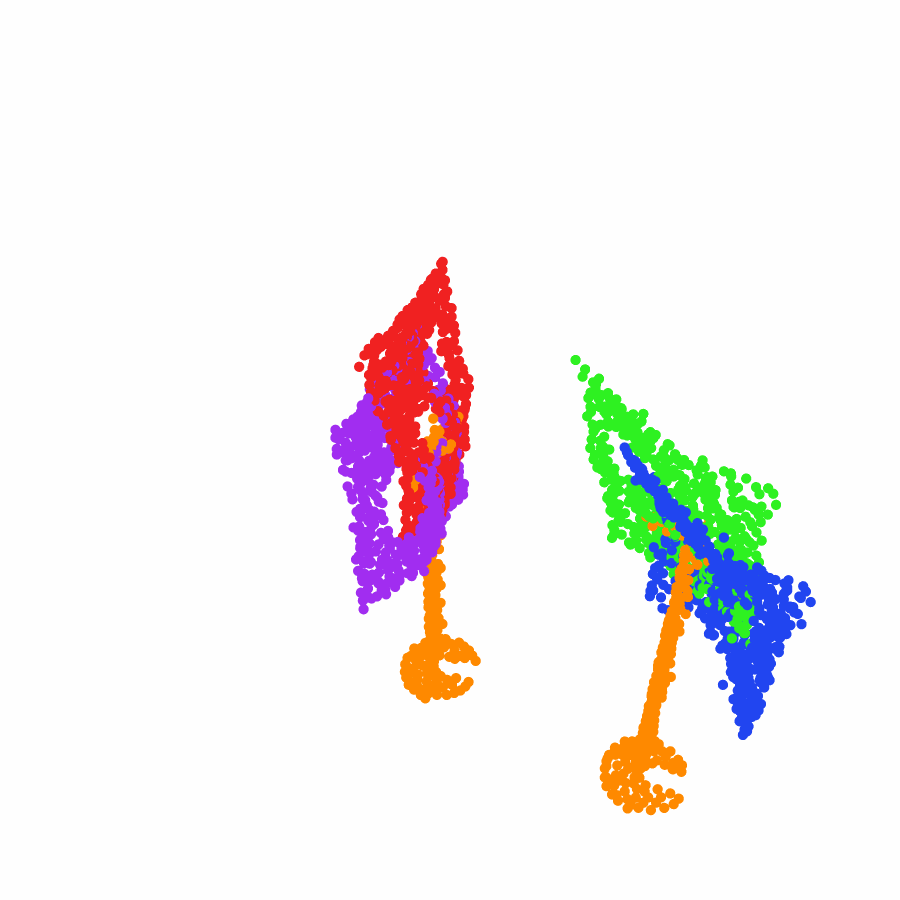Recent advances in robotic manipulation have highlighted the effectiveness of learning from demonstration. However, while end-to-end policies excel in expressivity and flexibility,
they struggle both in generalizing to novel object geometries and in attaining a high degree of precision. An alternative, object-centric approach frames the task as predicting the
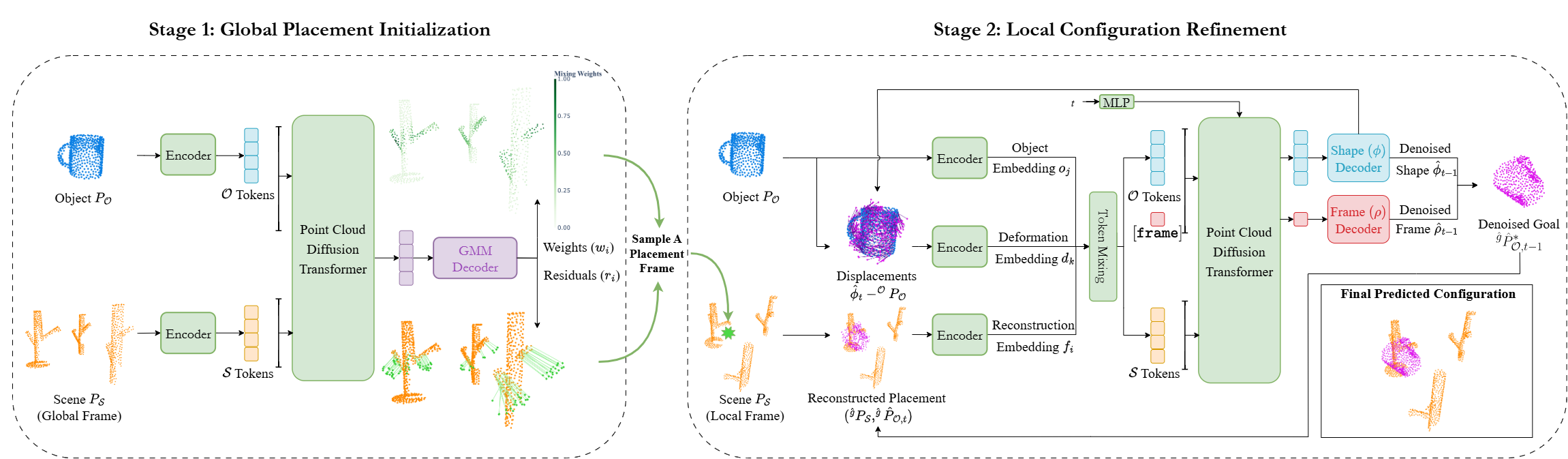
placement pose of the target object, providing a modular decomposition of the problem. Building on this goal-prediction paradigm, we propose a hierarchical, disentangled point diffusion
framework that achieves state-of-the-art performance in placement precision, multi-modal coverage, and generalization to variations in object geometries and scene configurations.
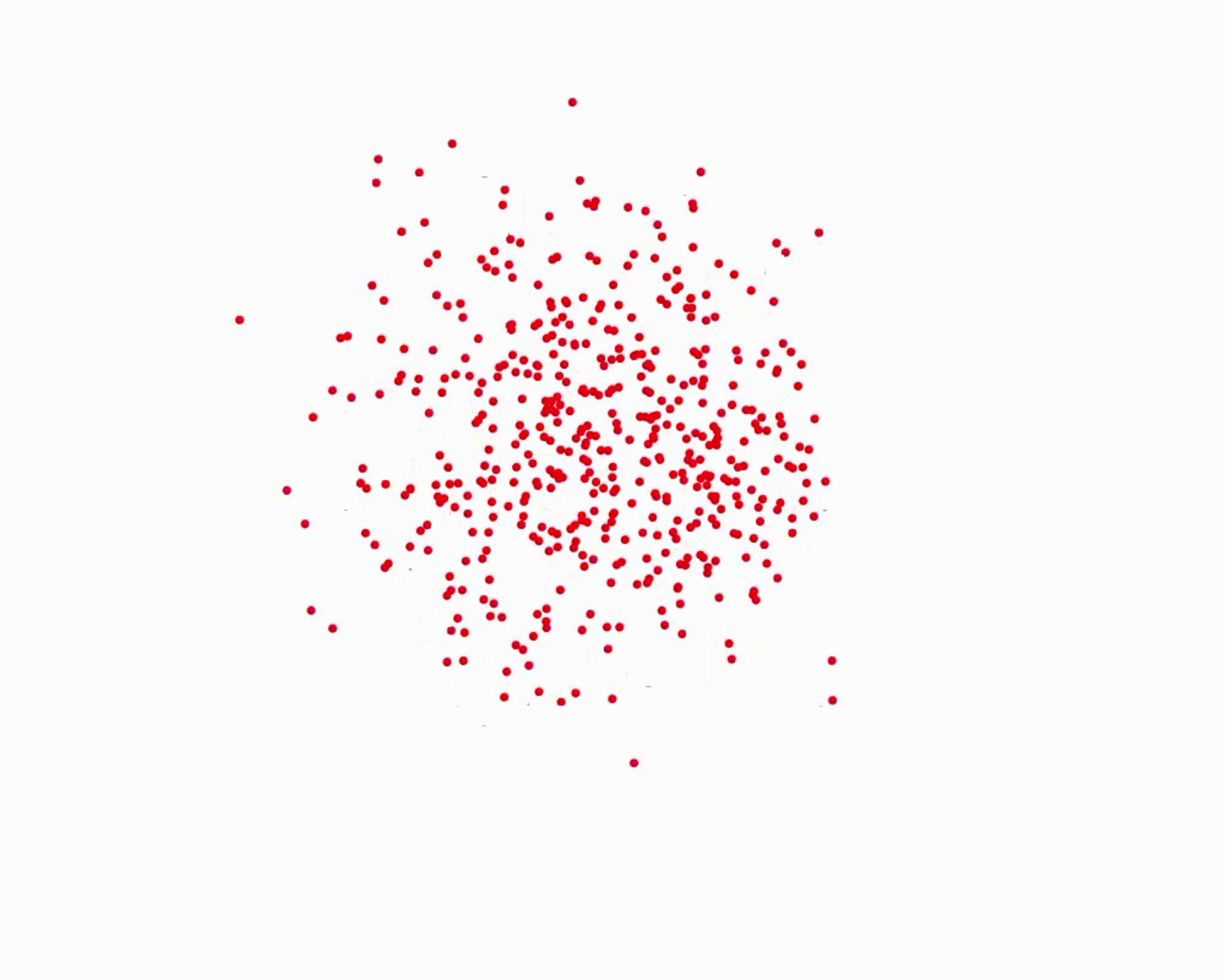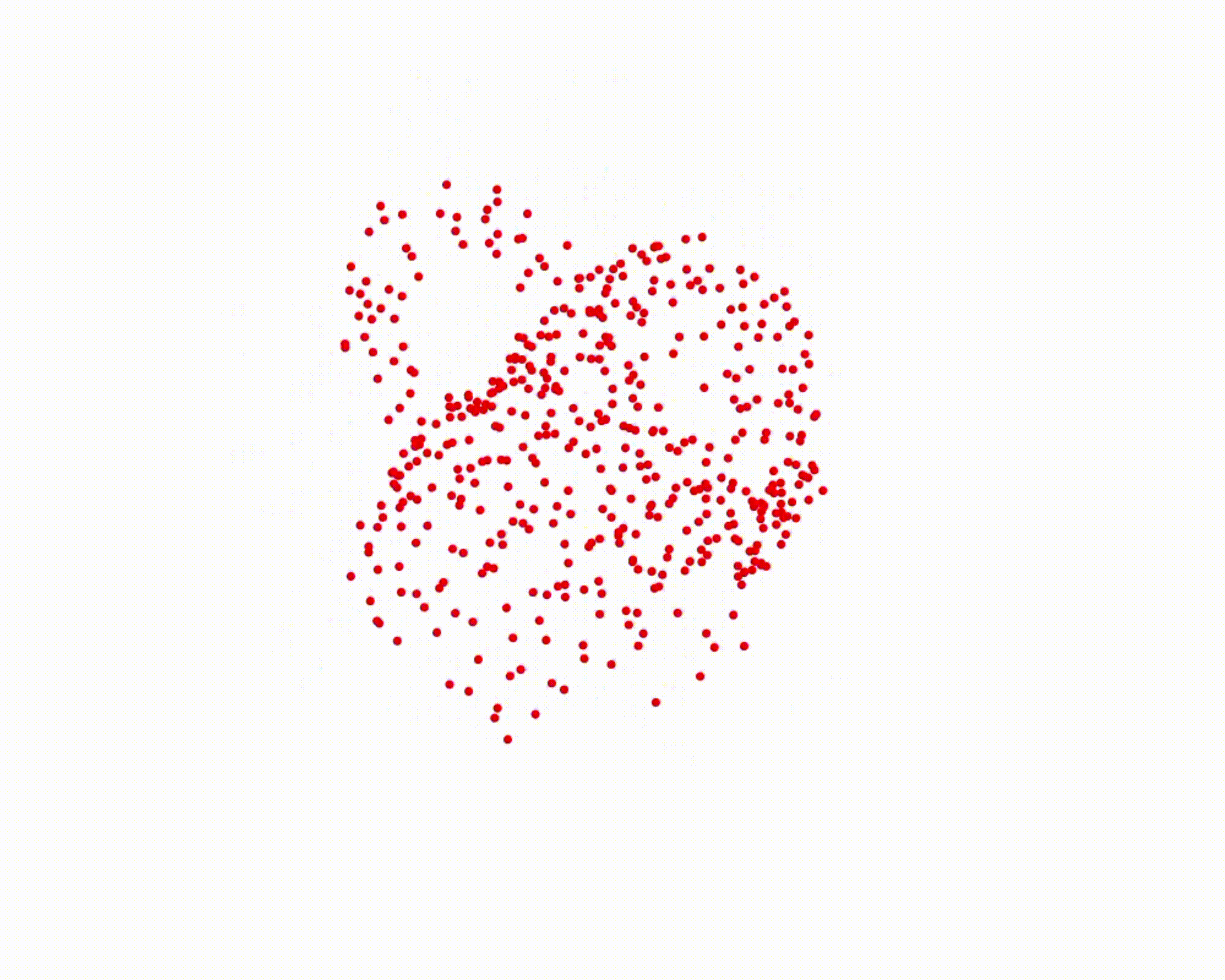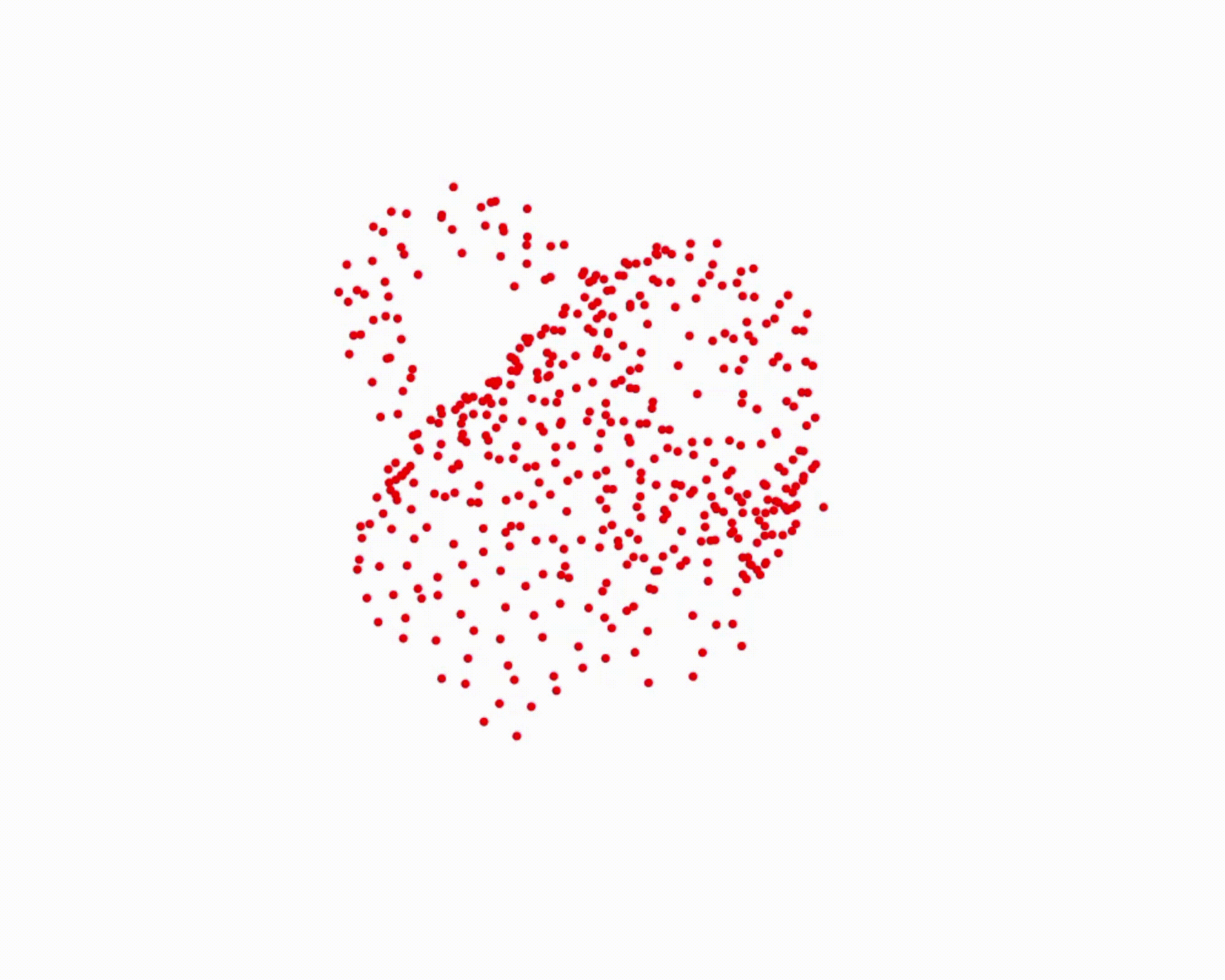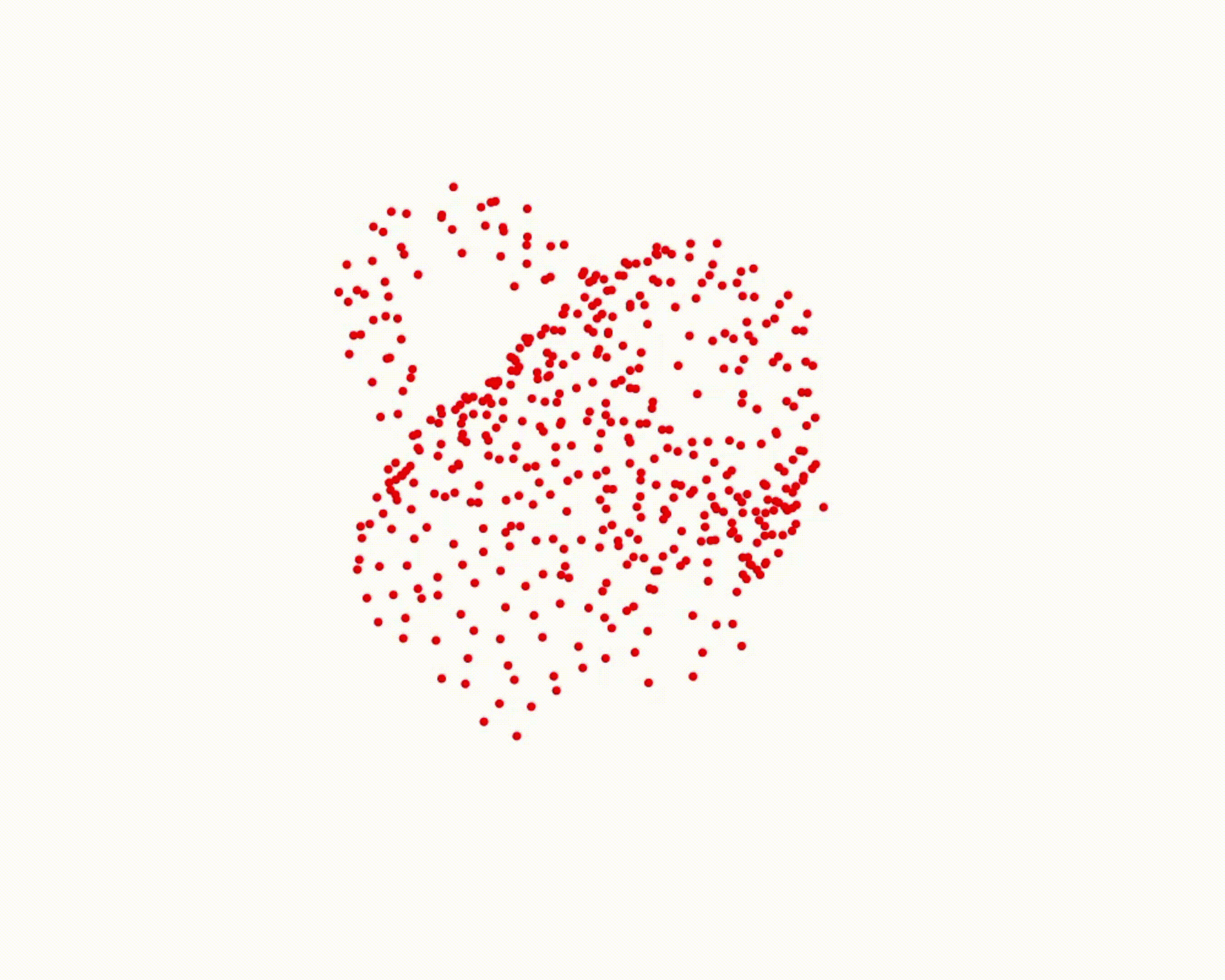
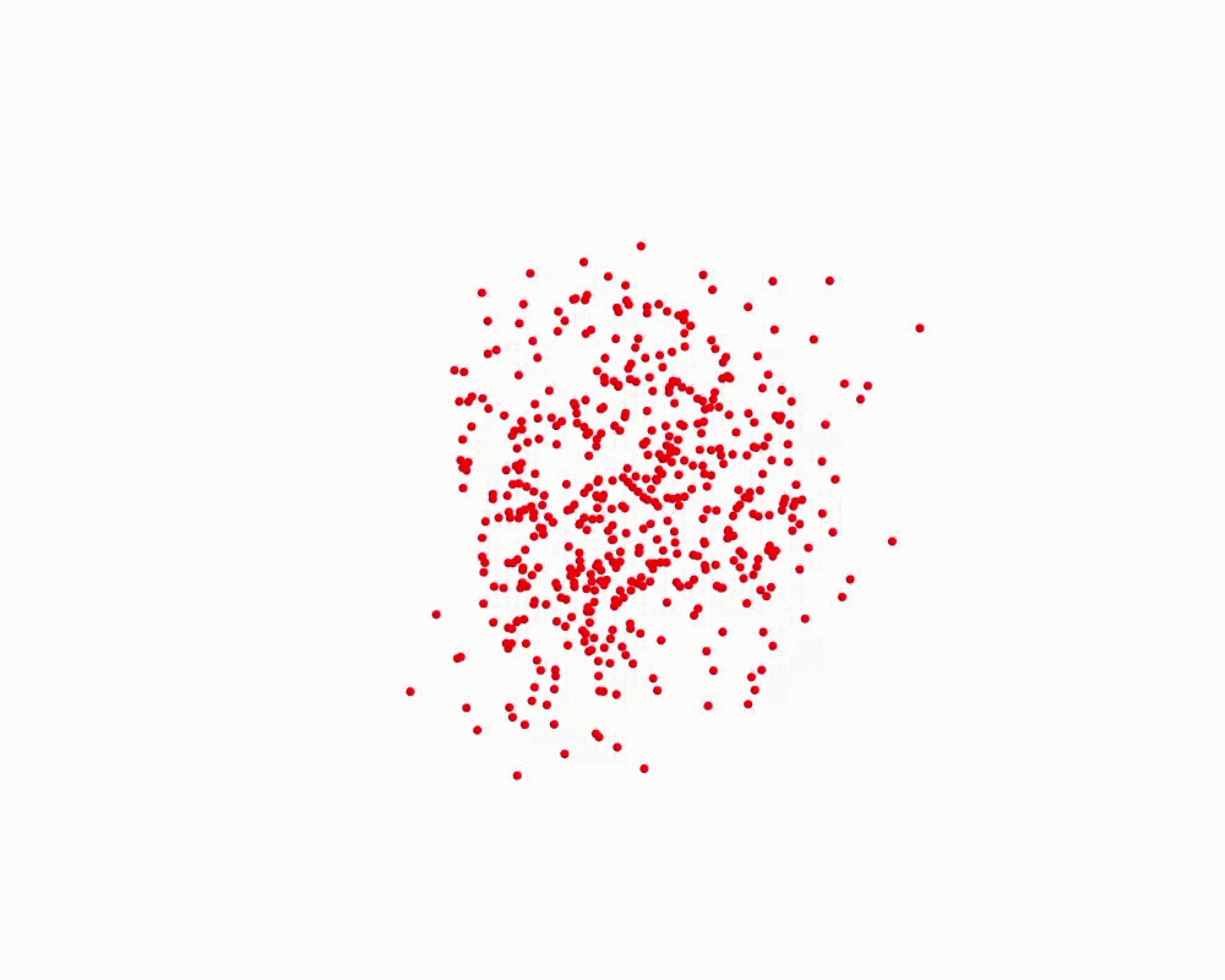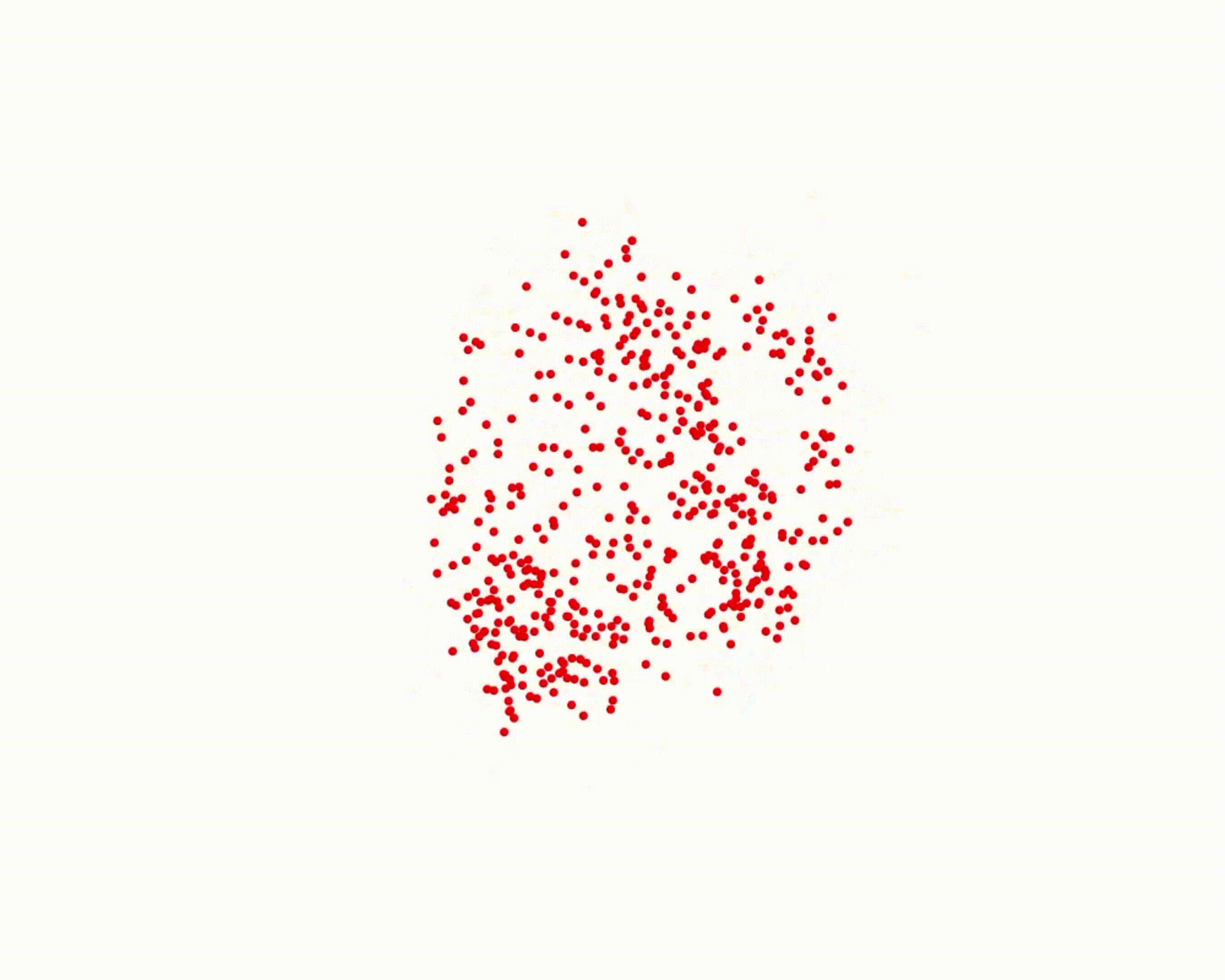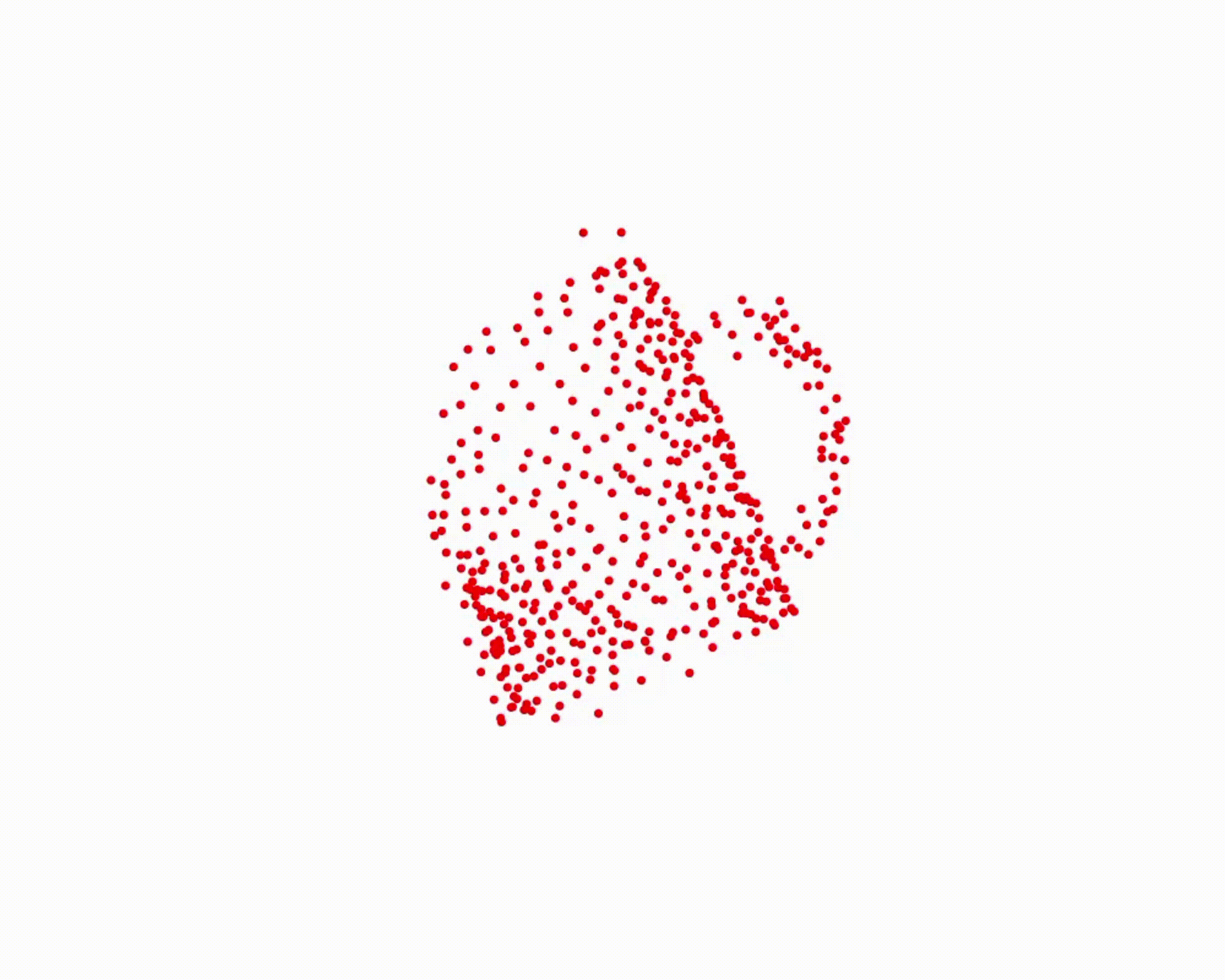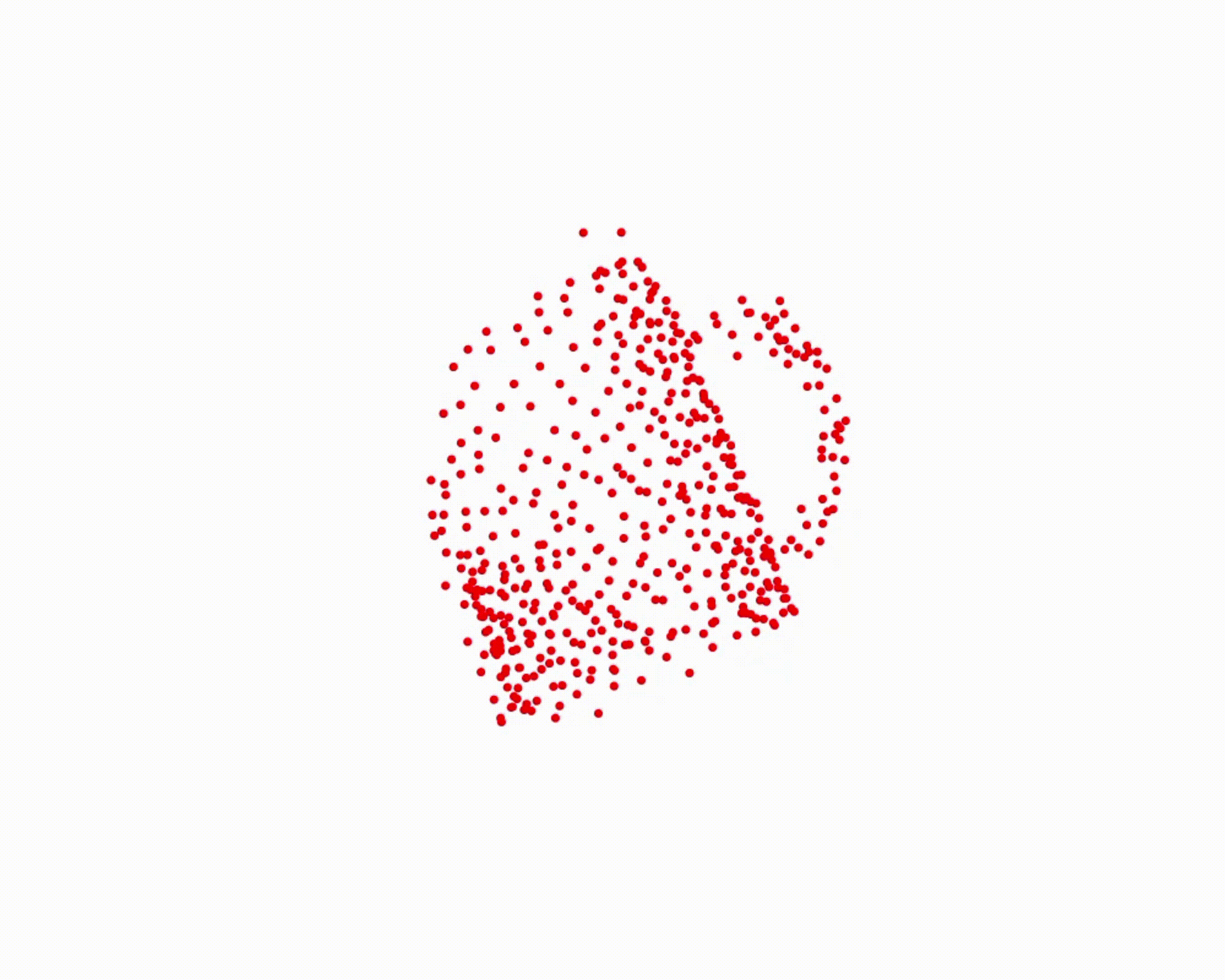
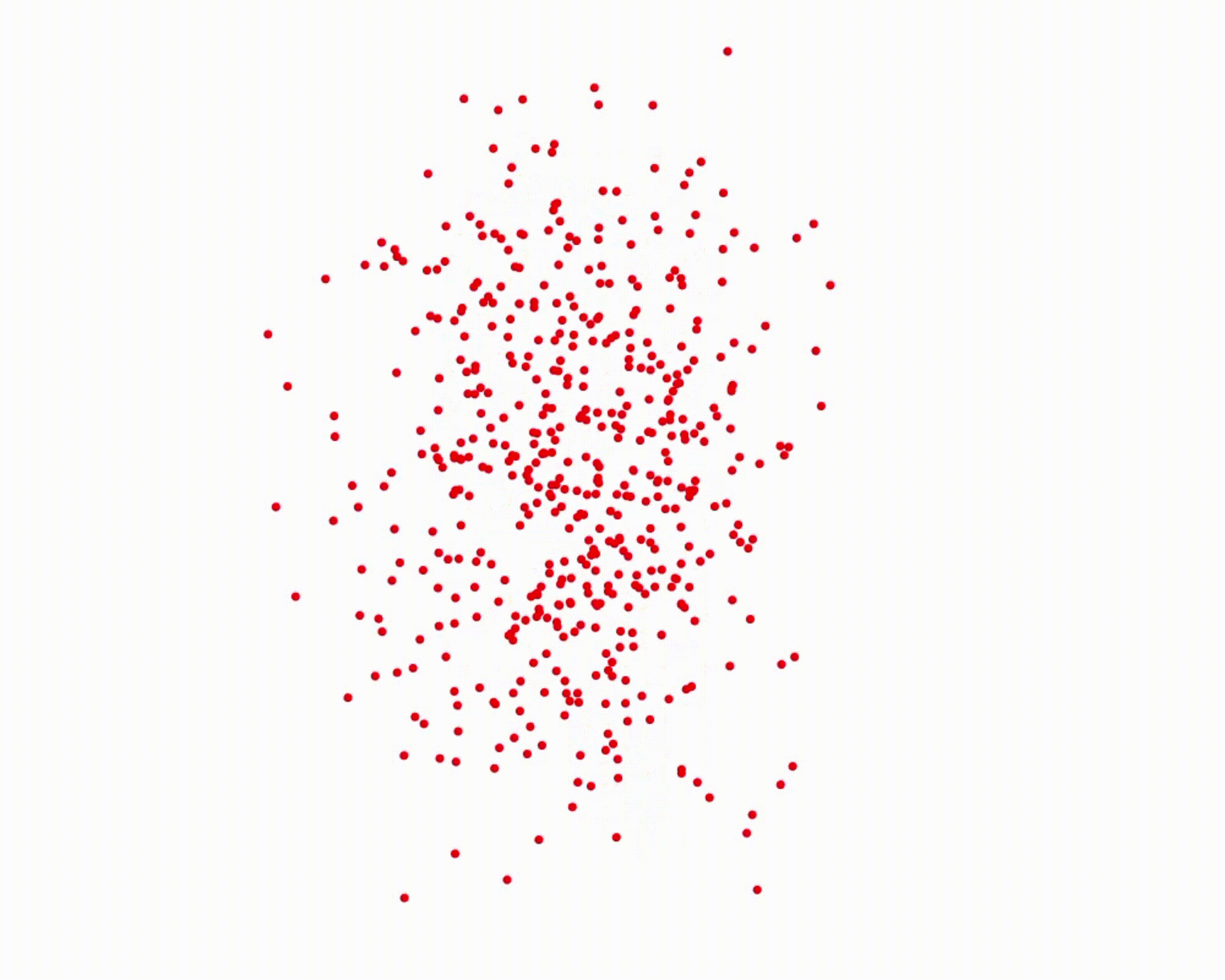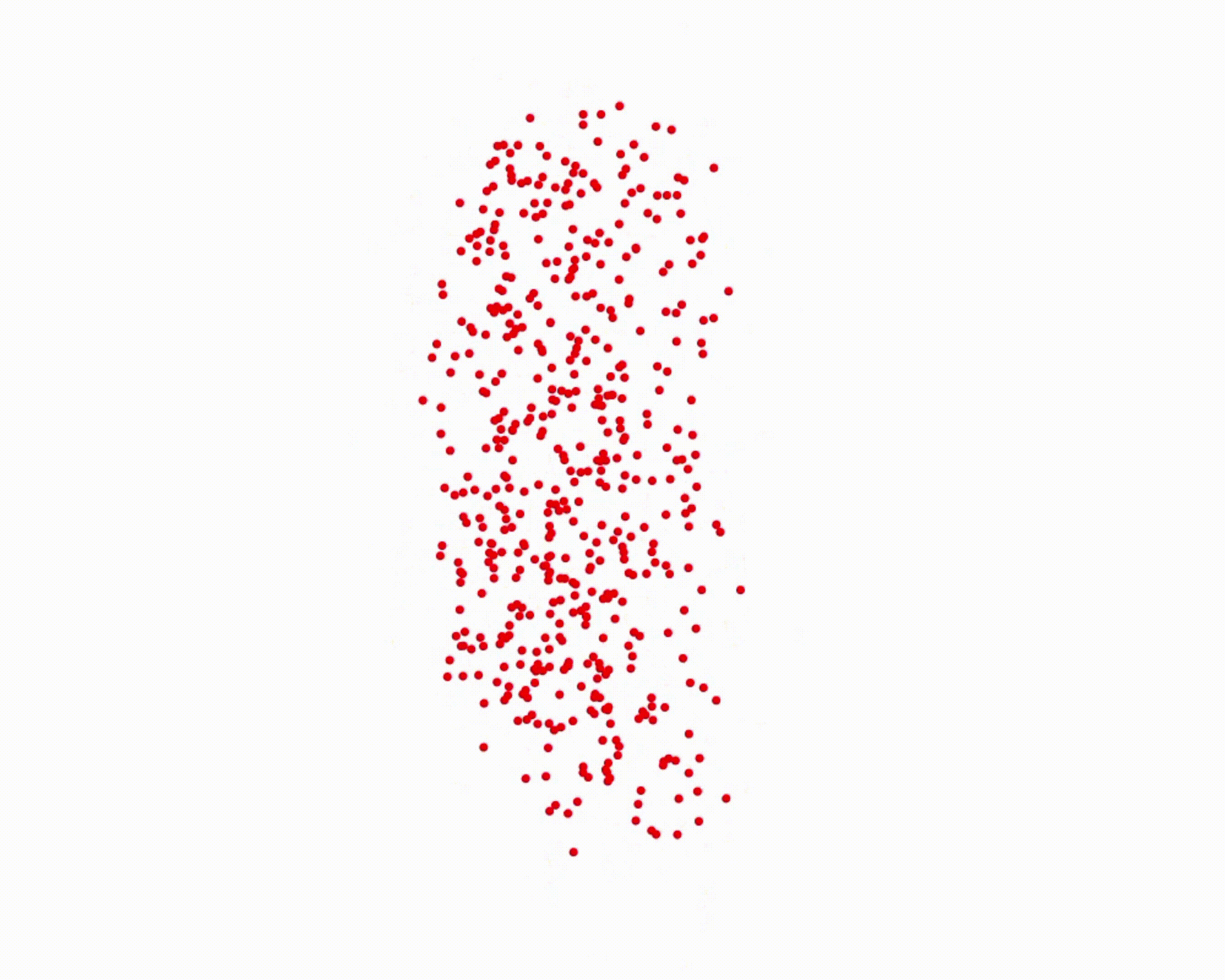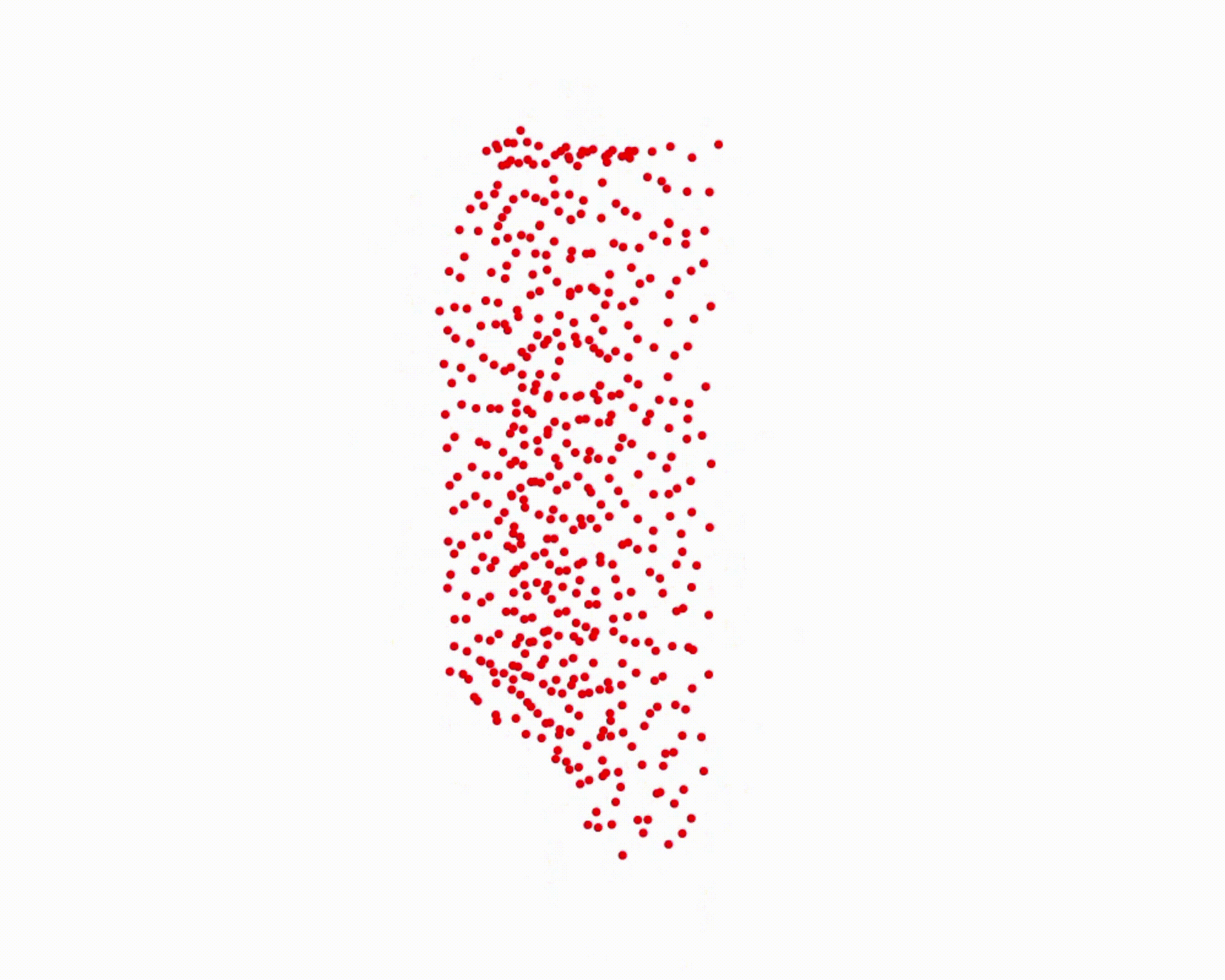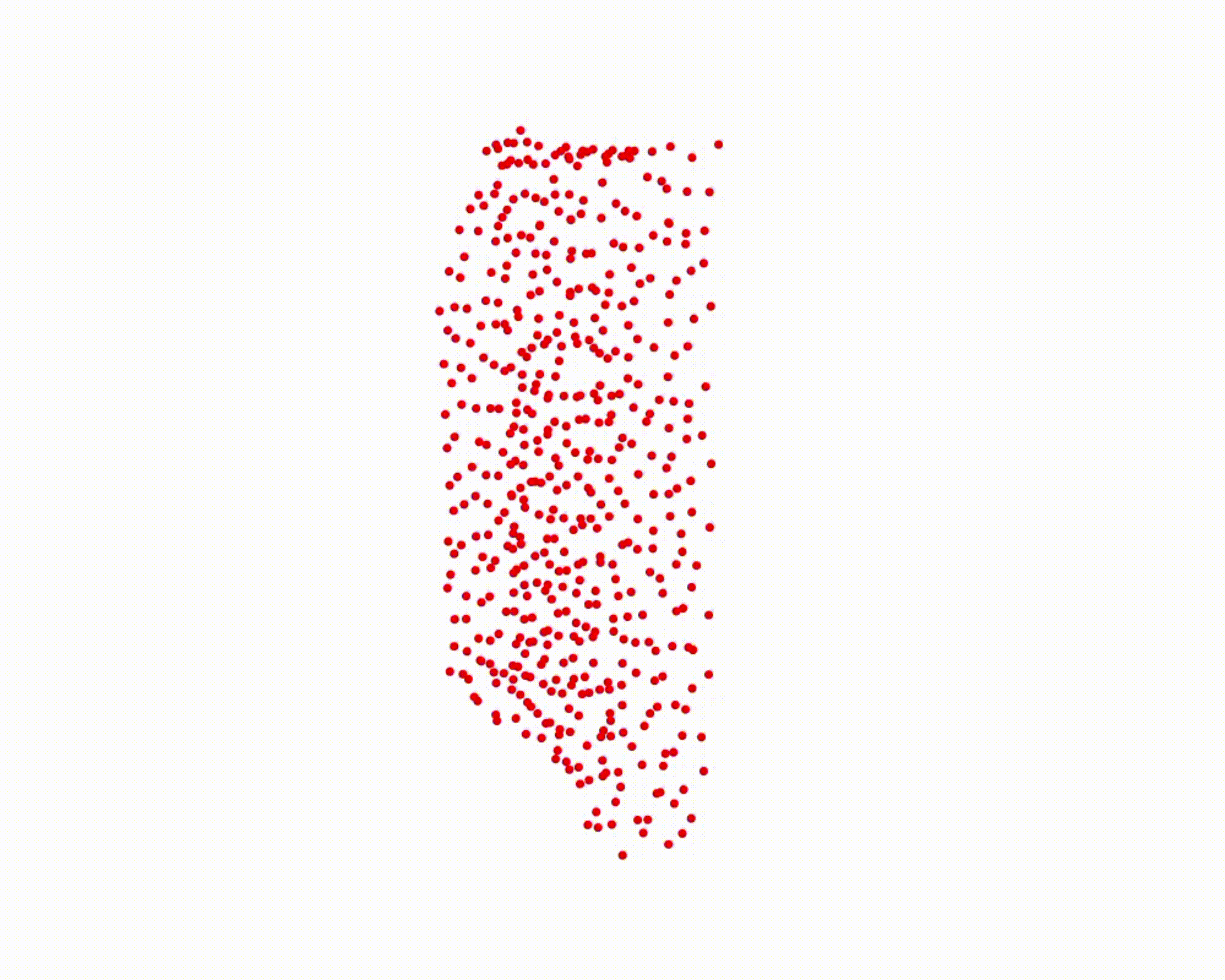
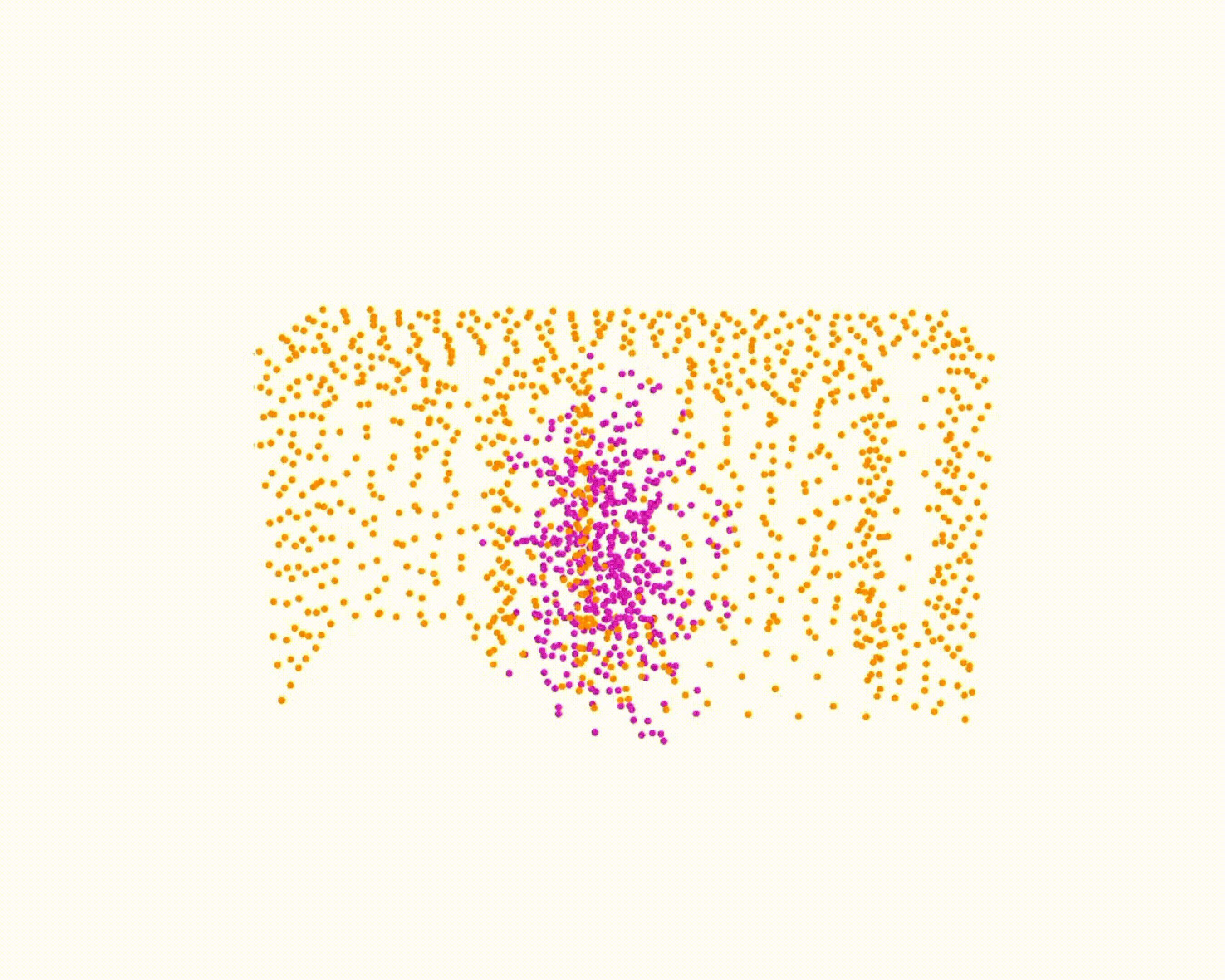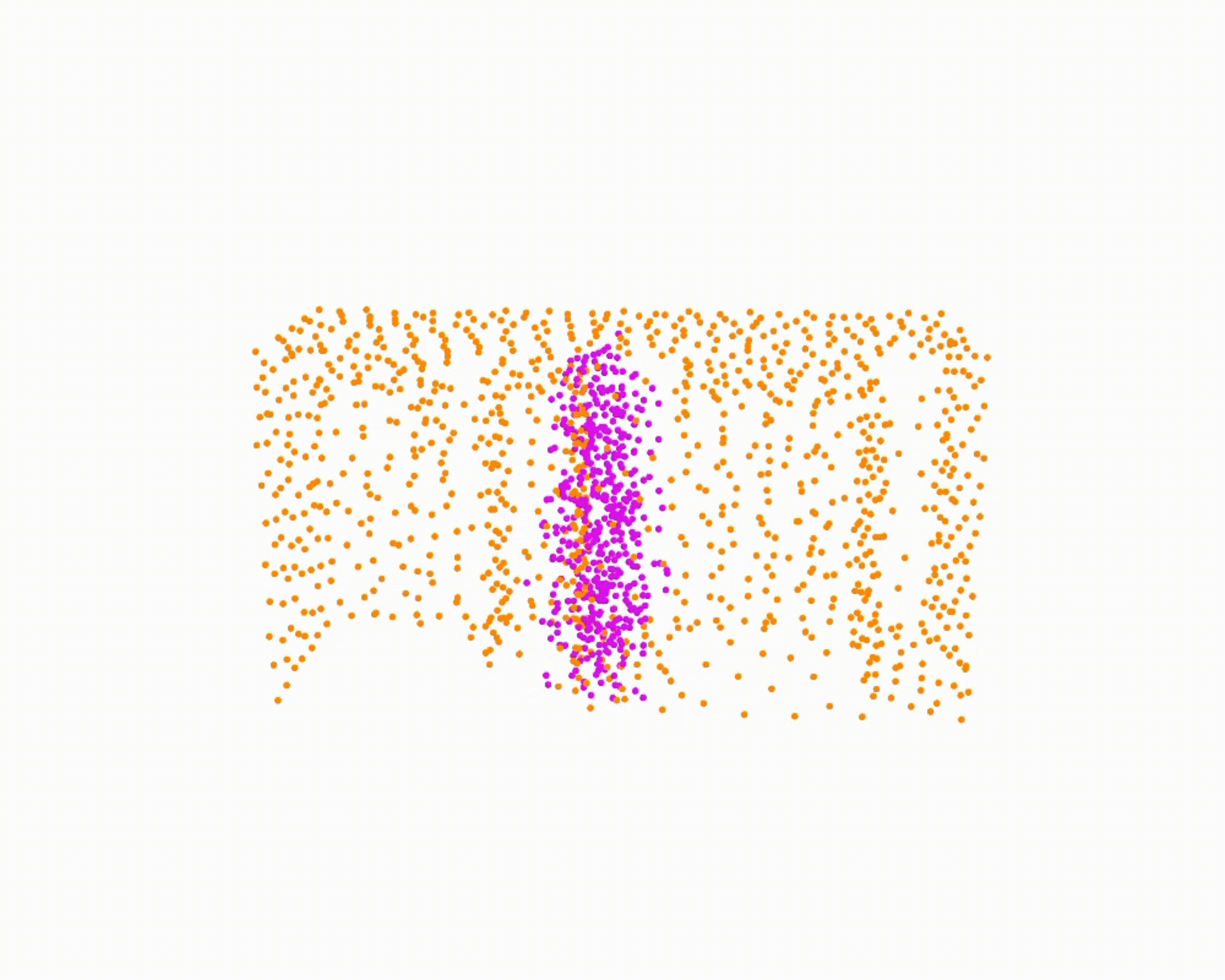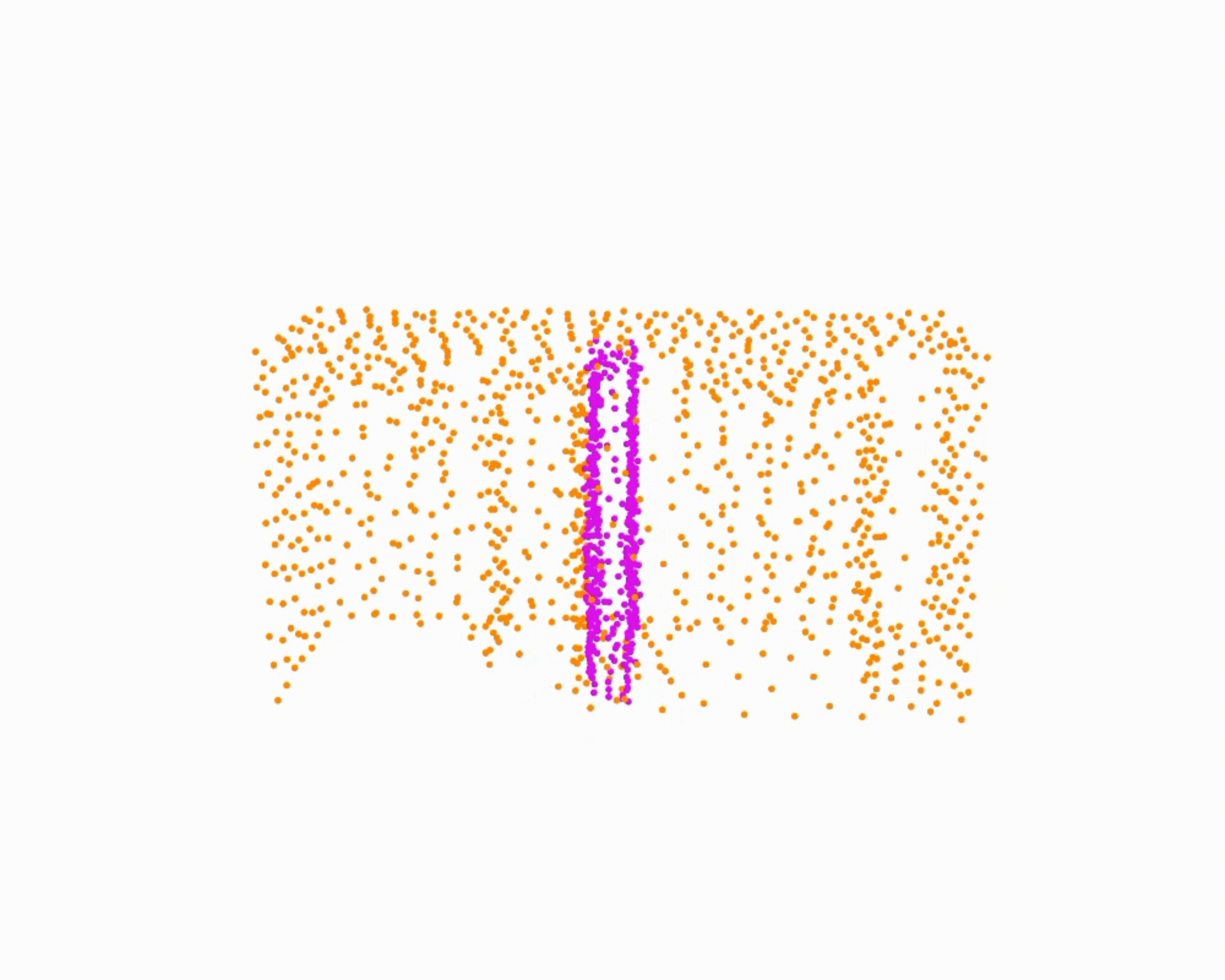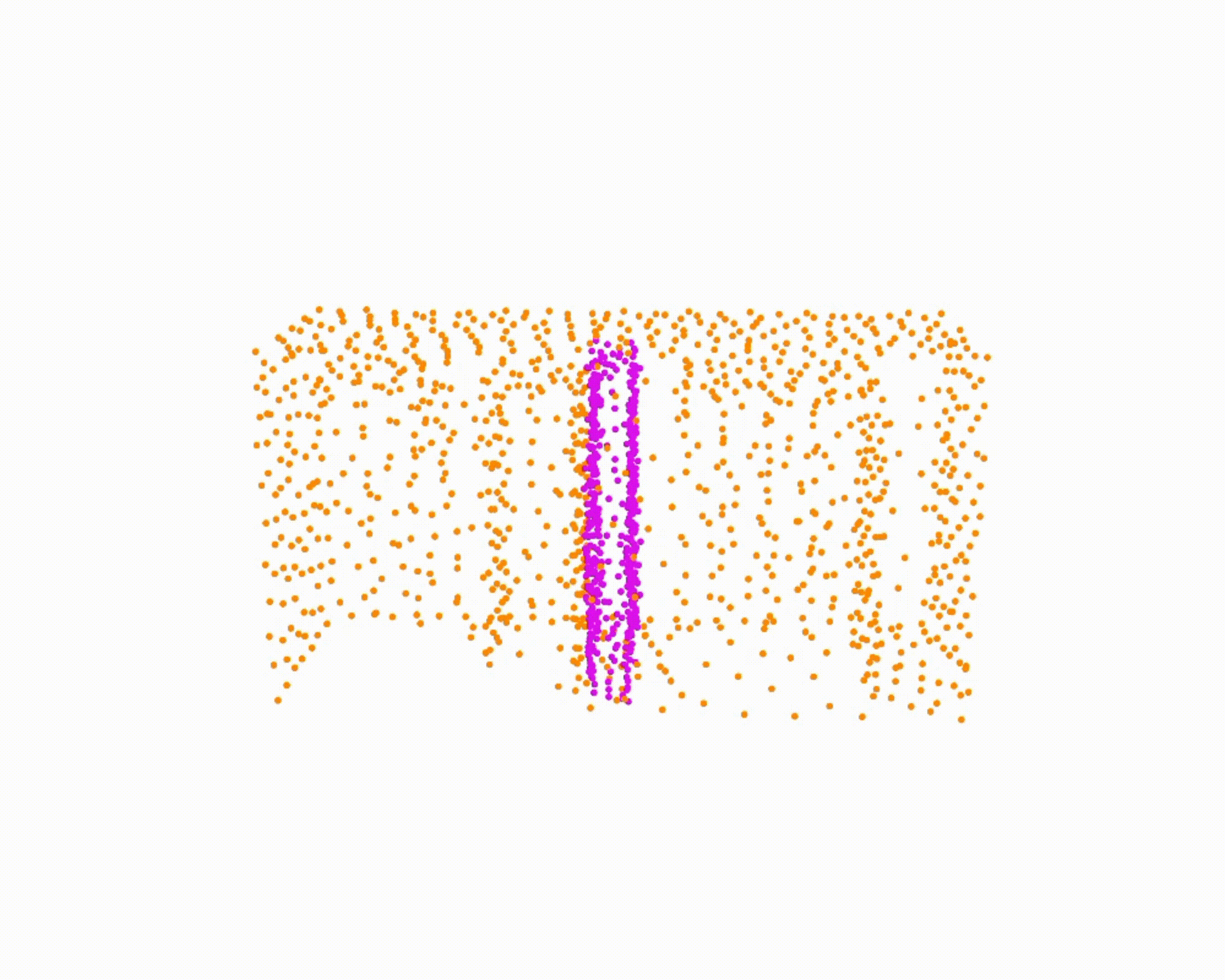
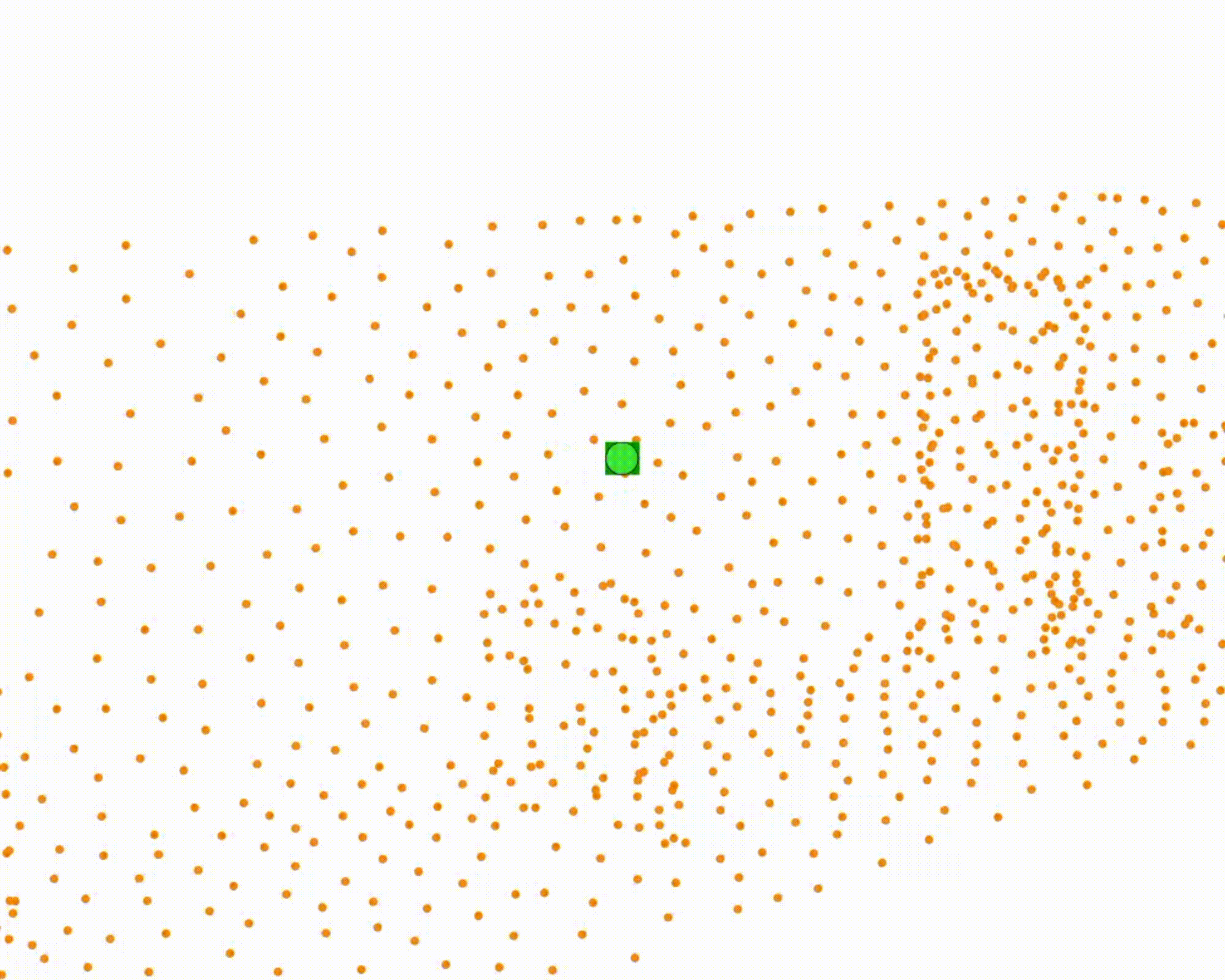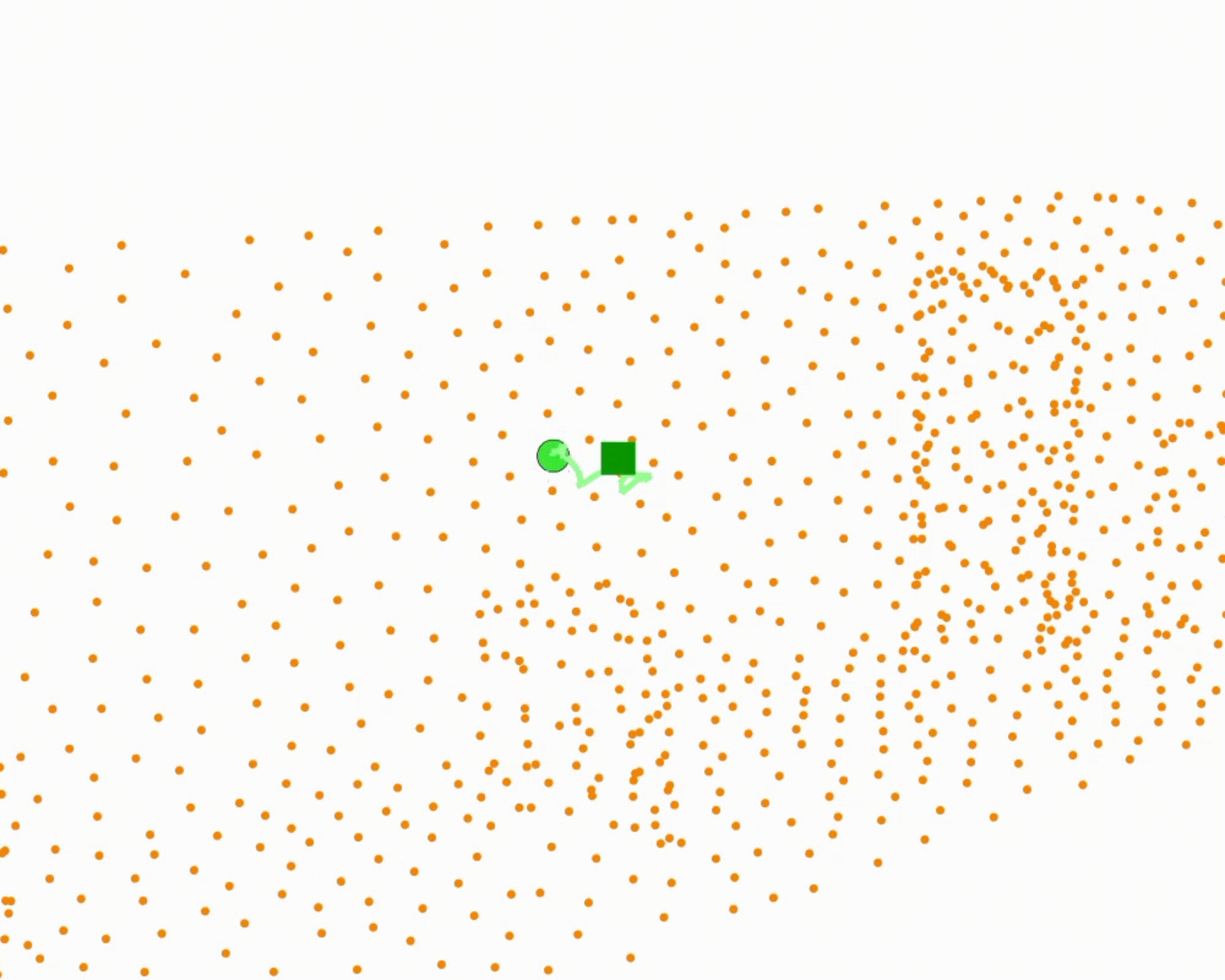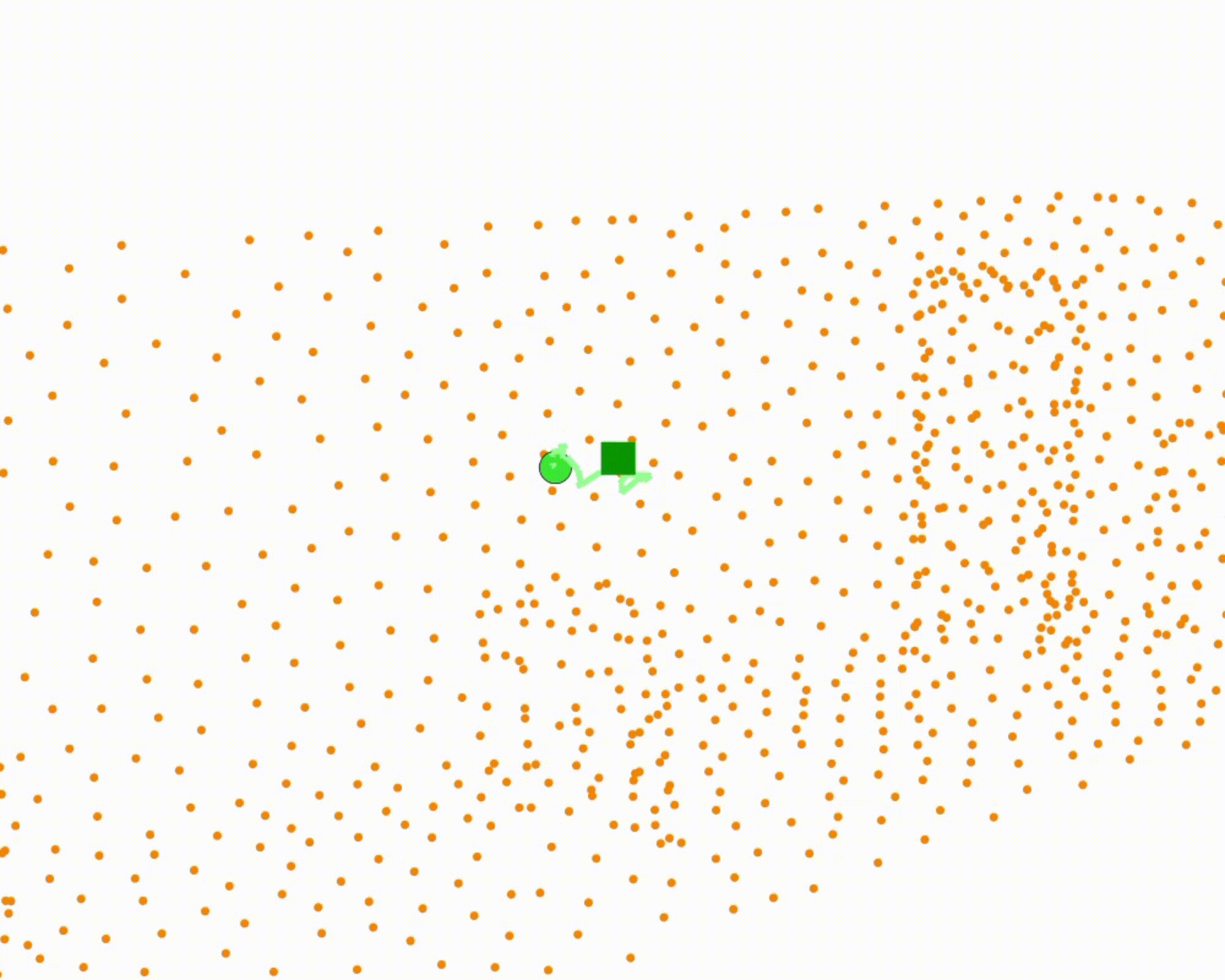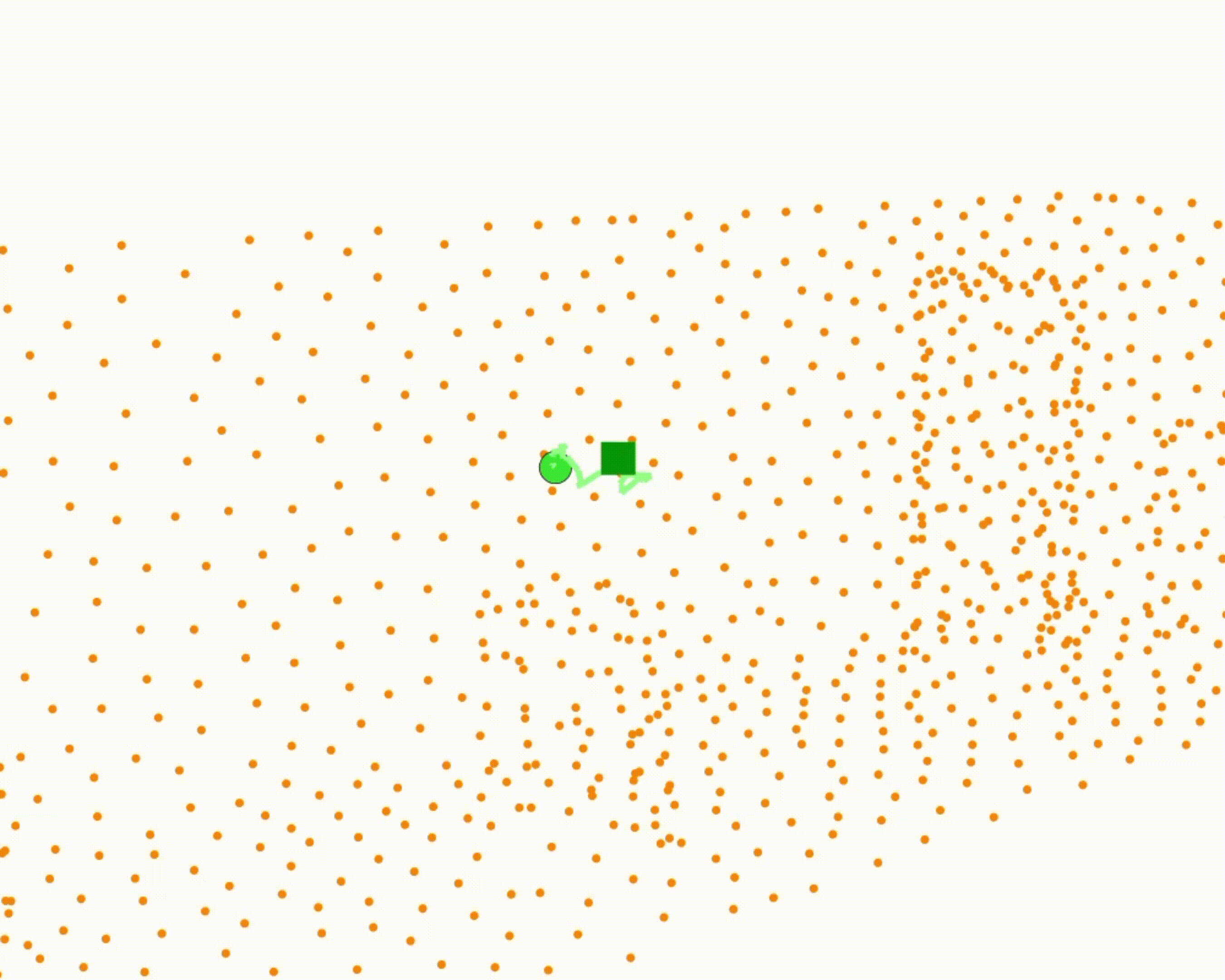
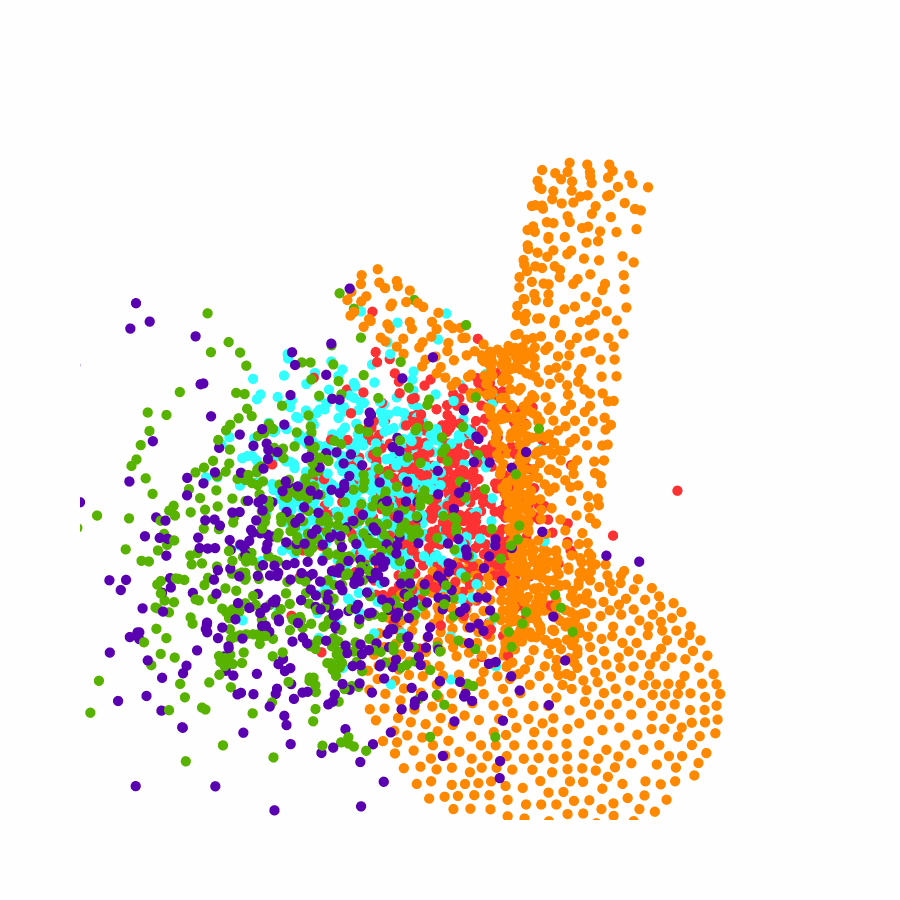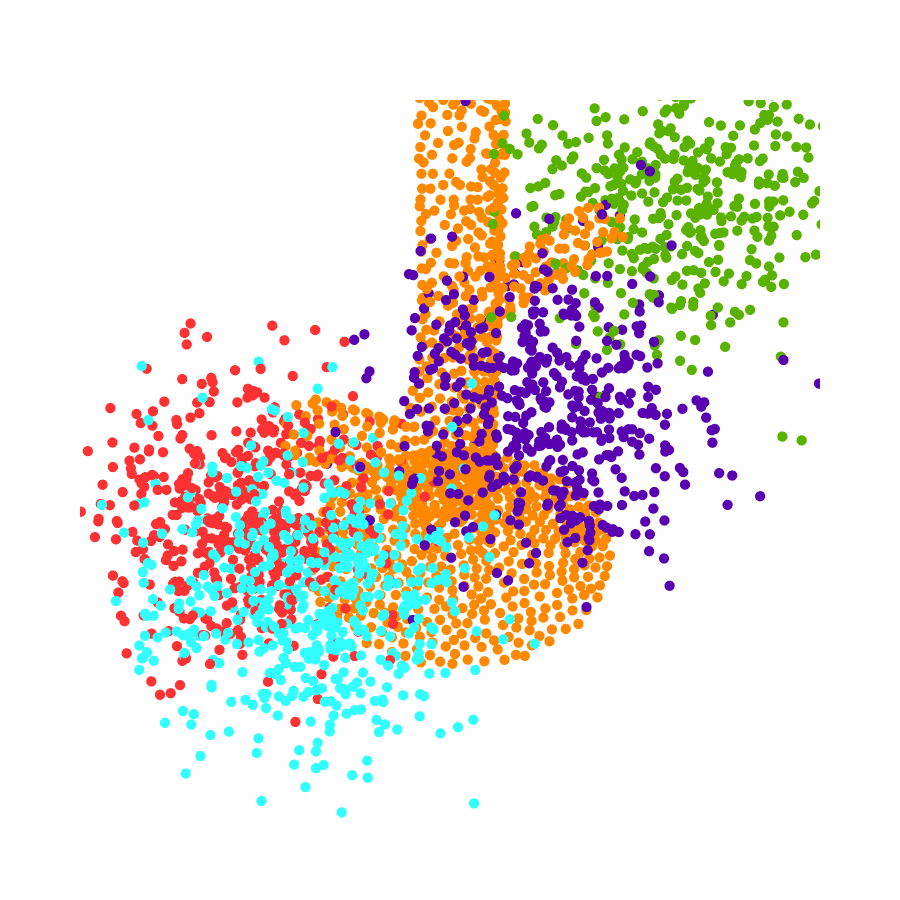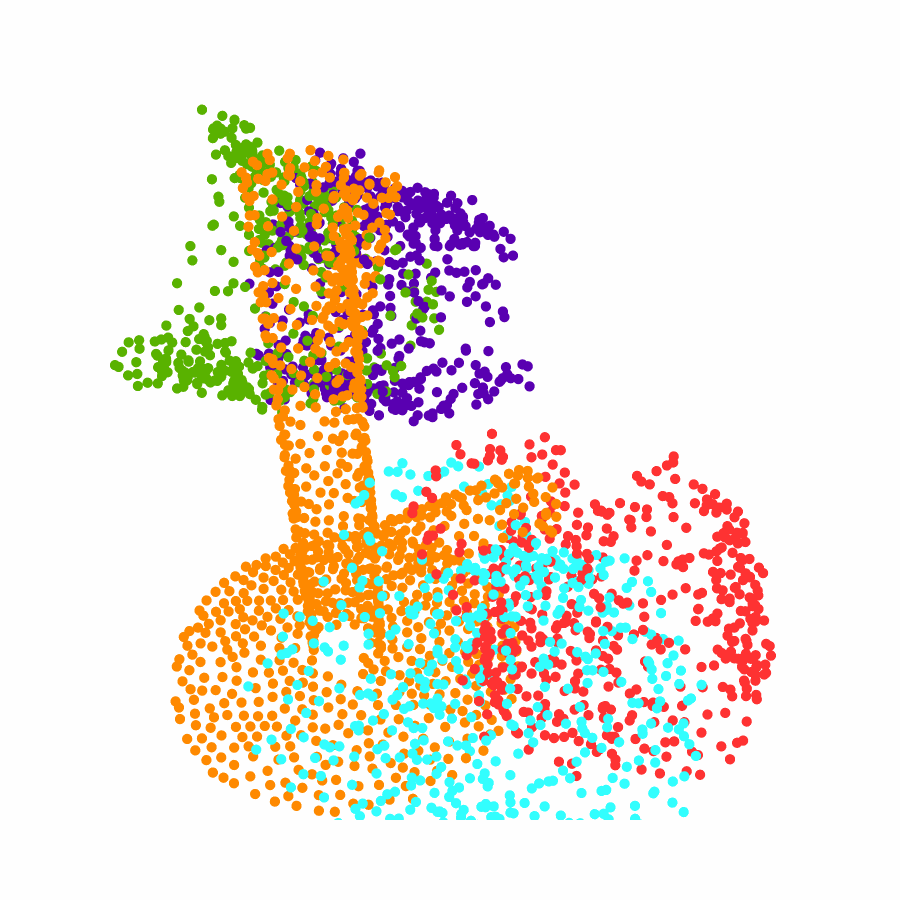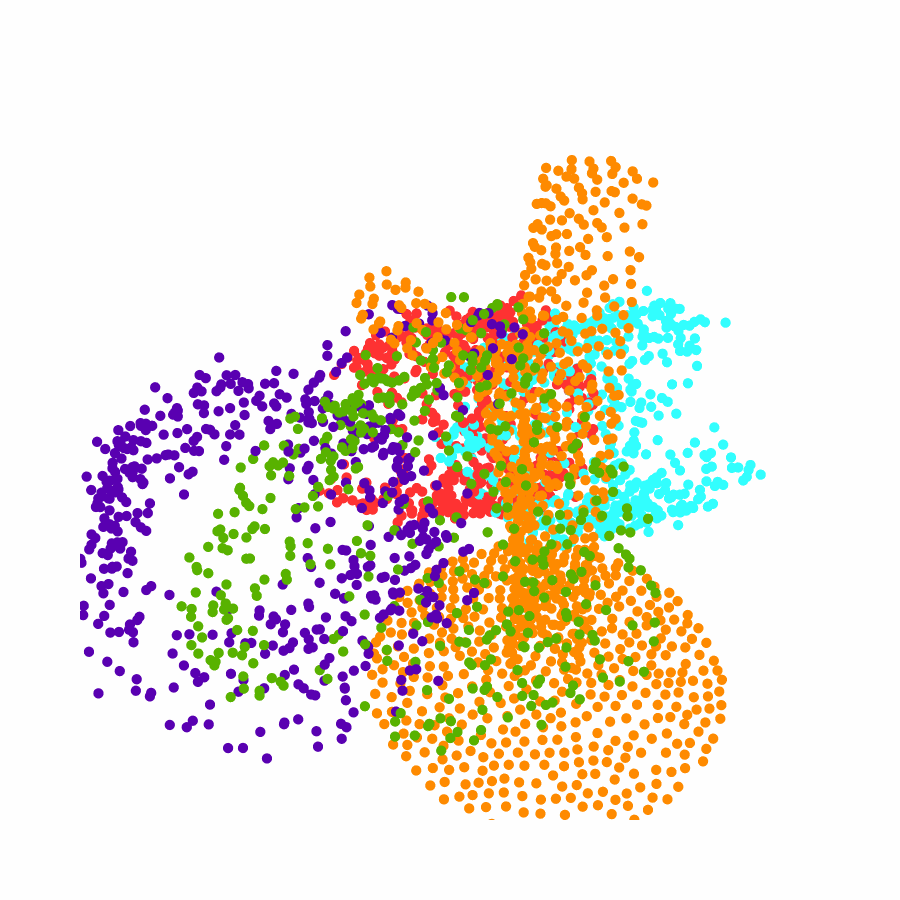
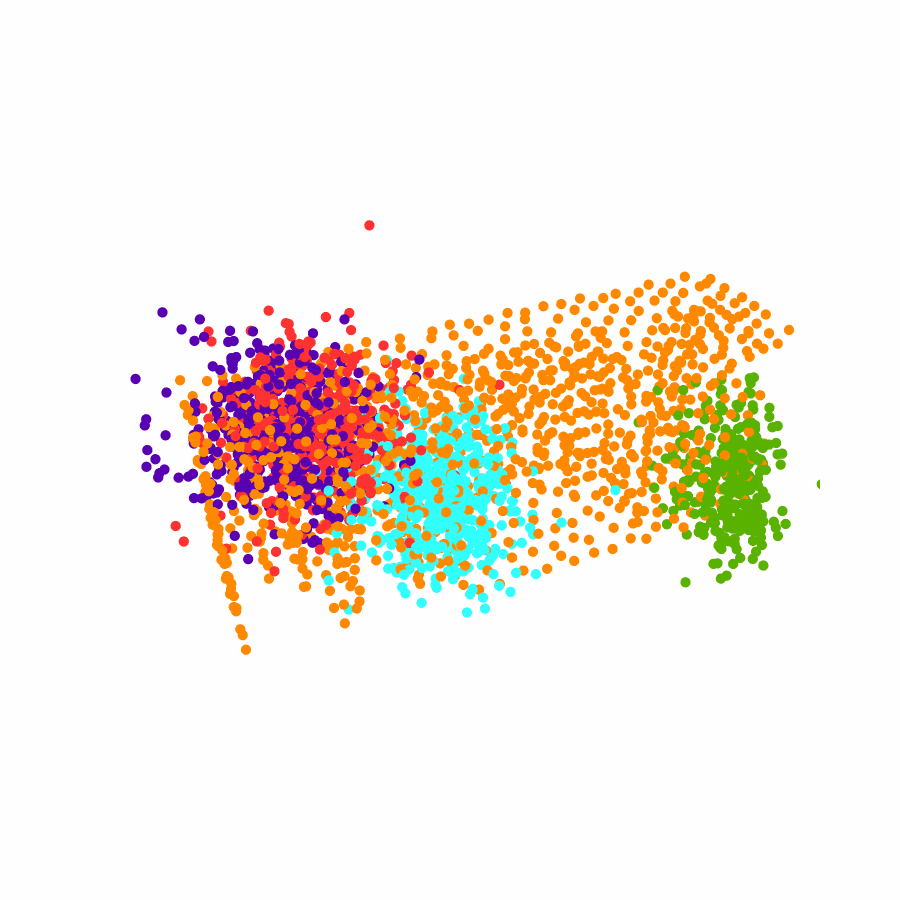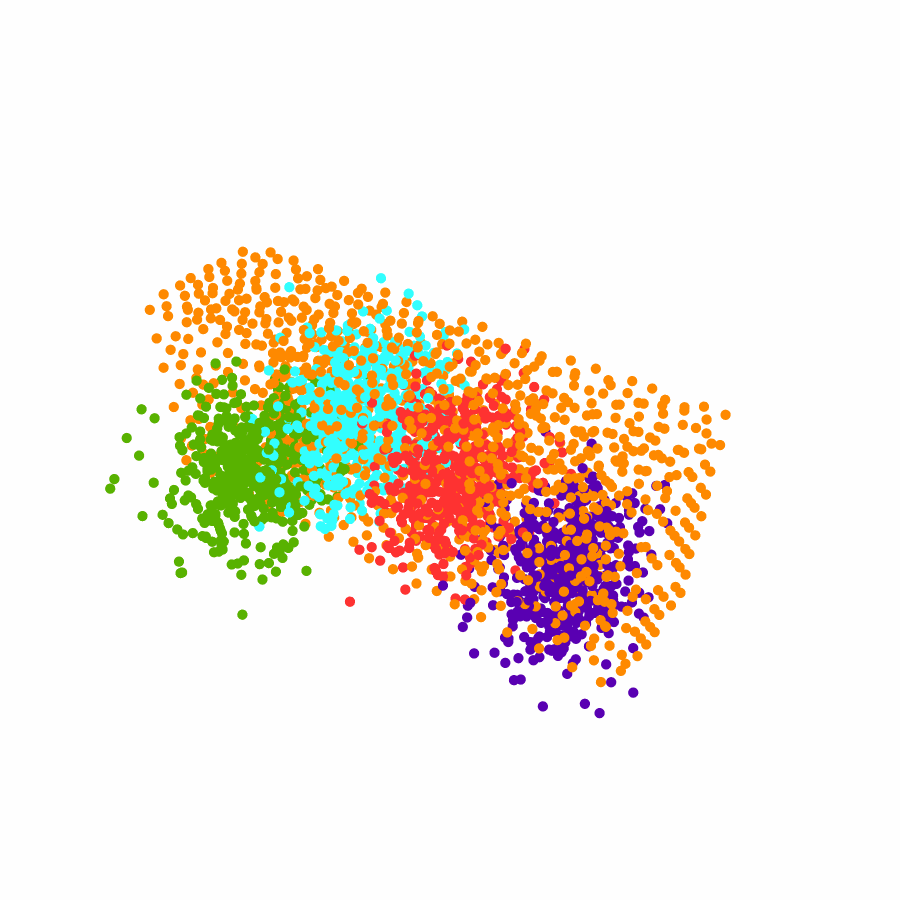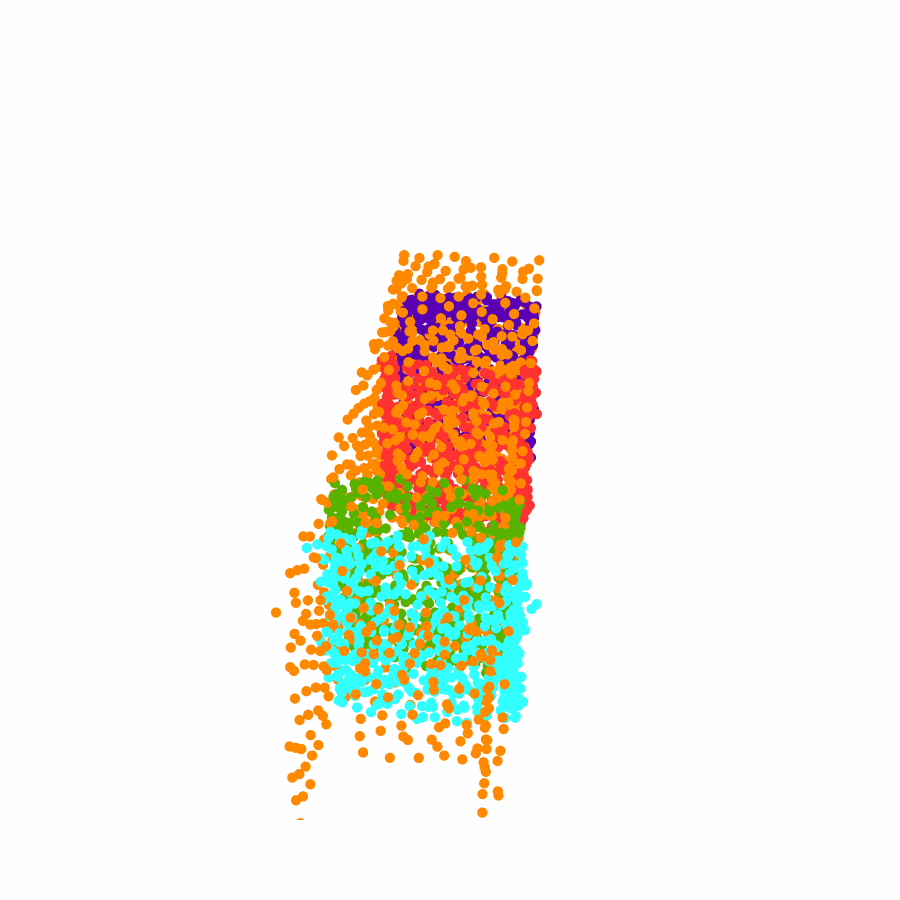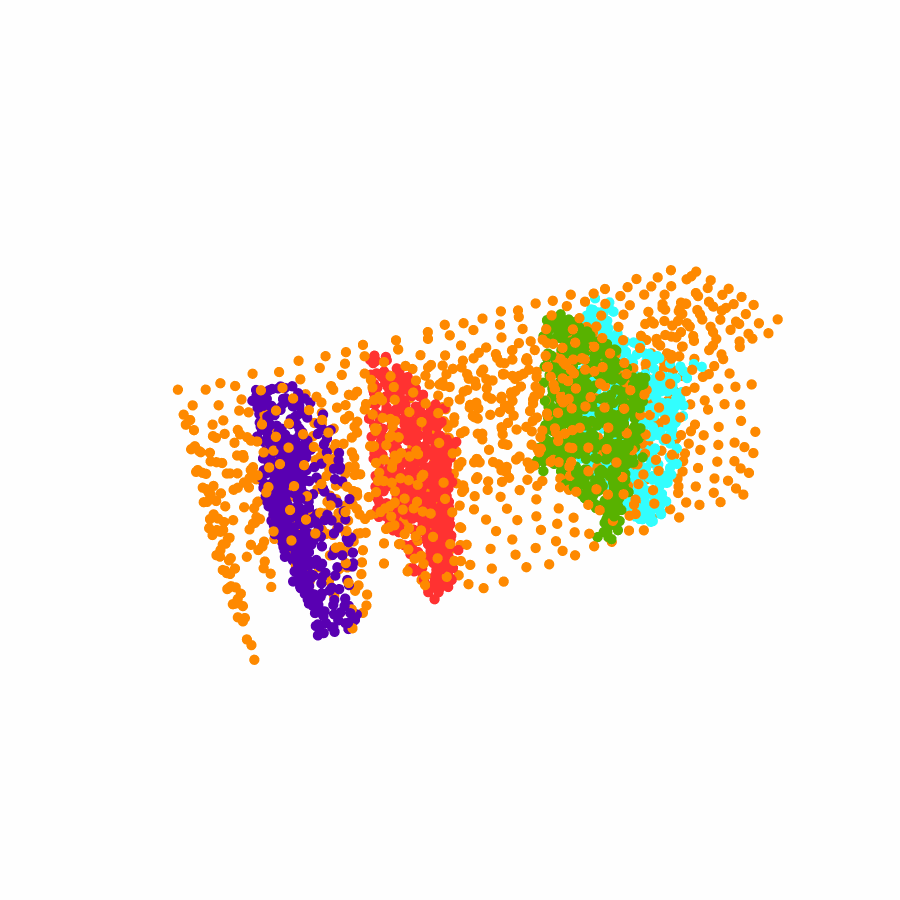
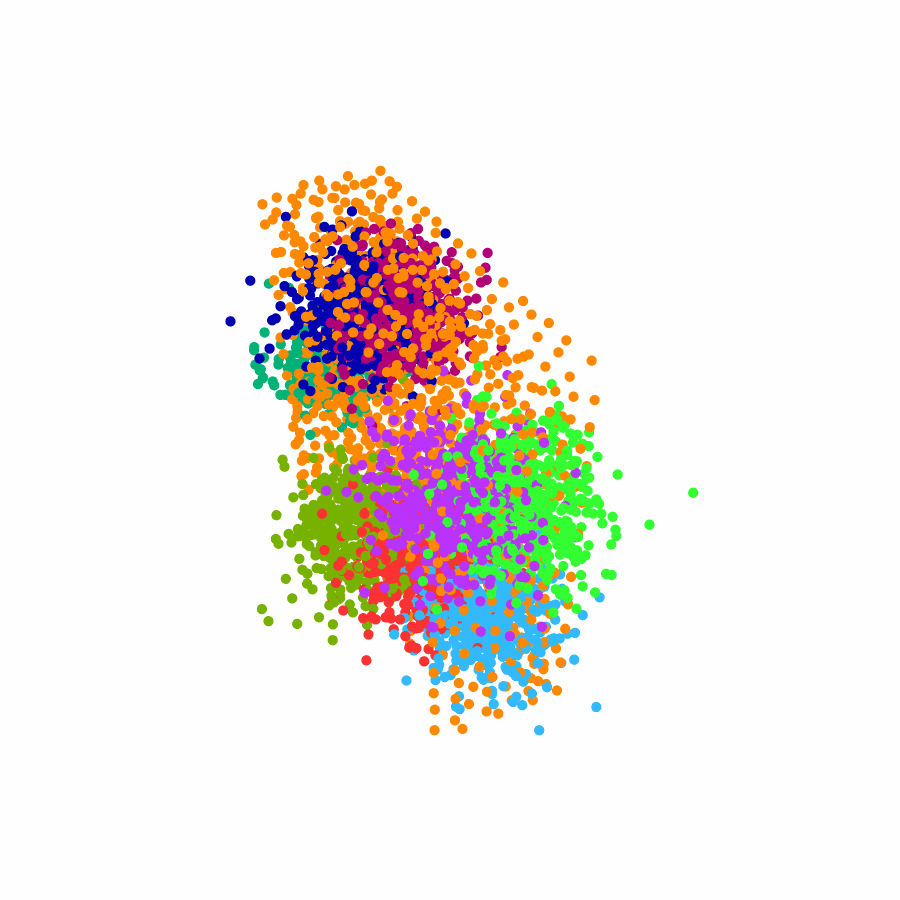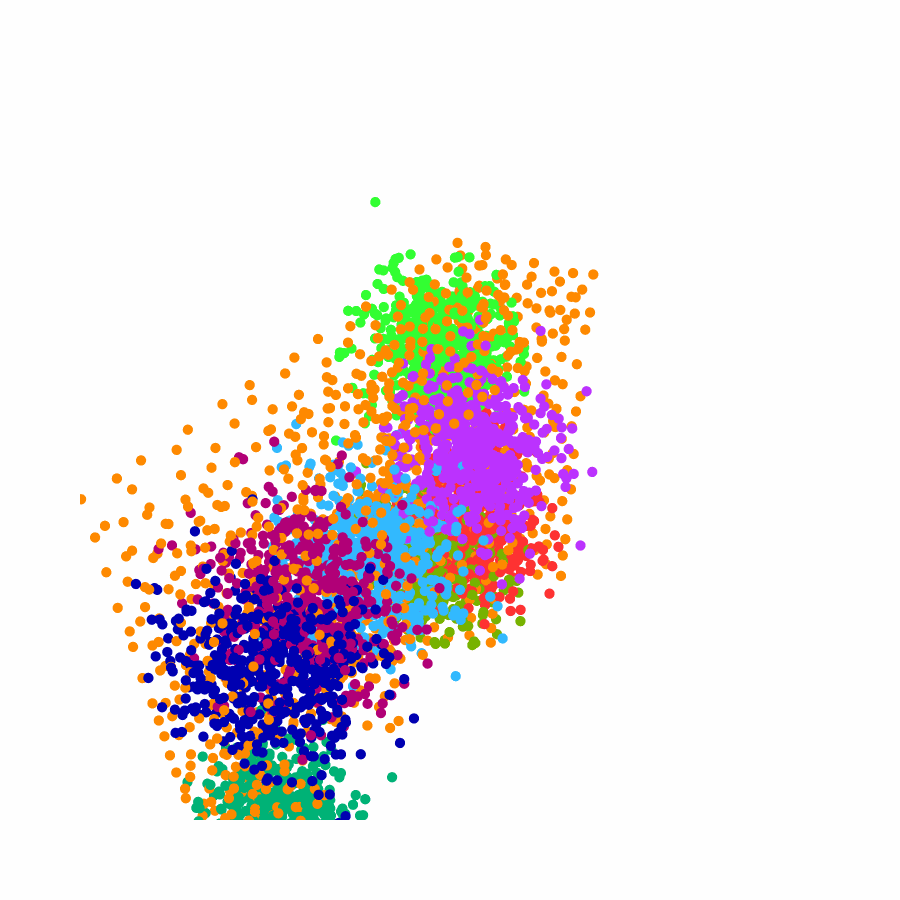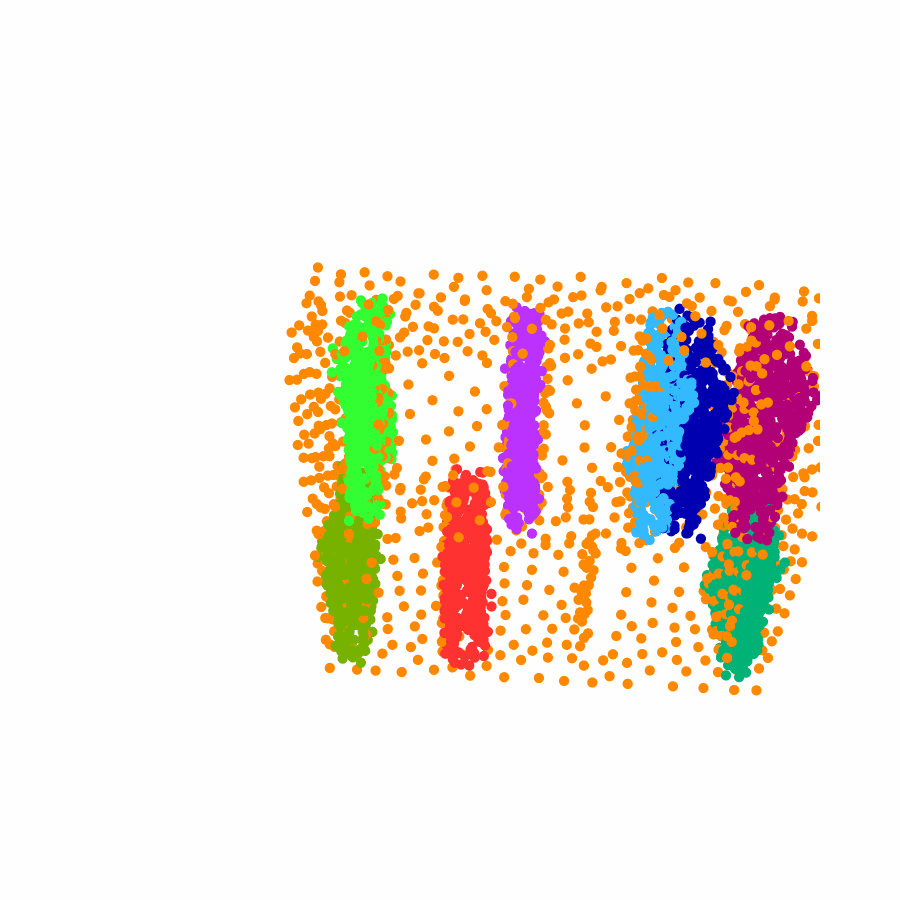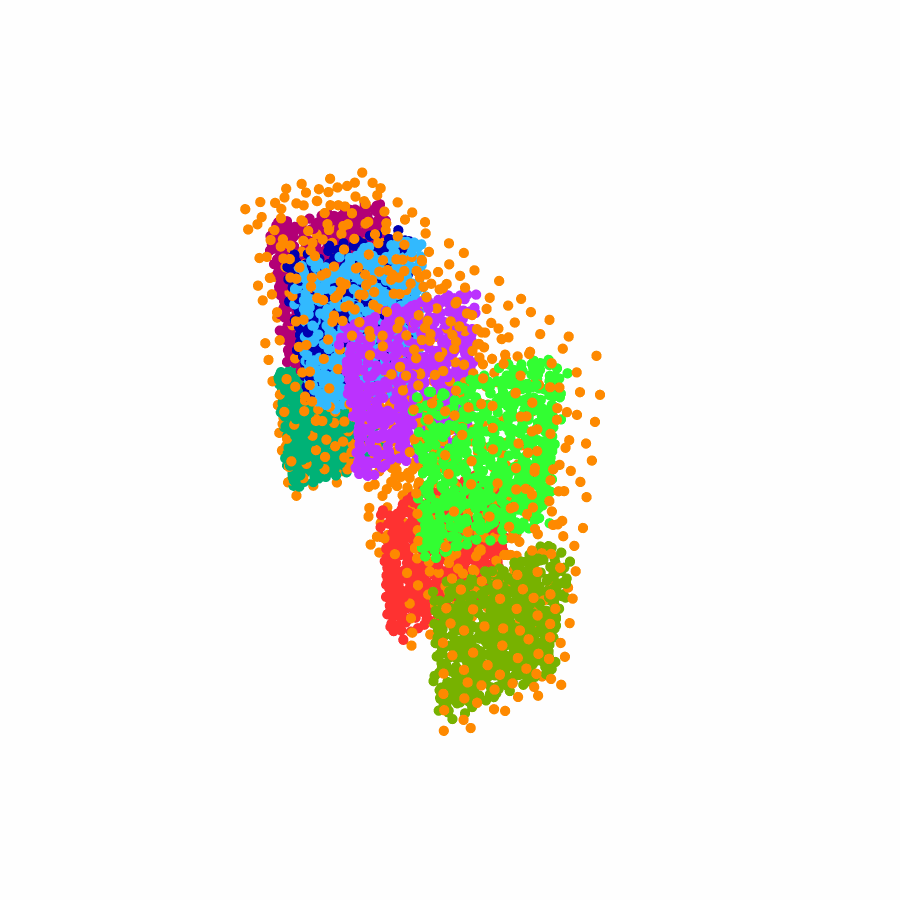
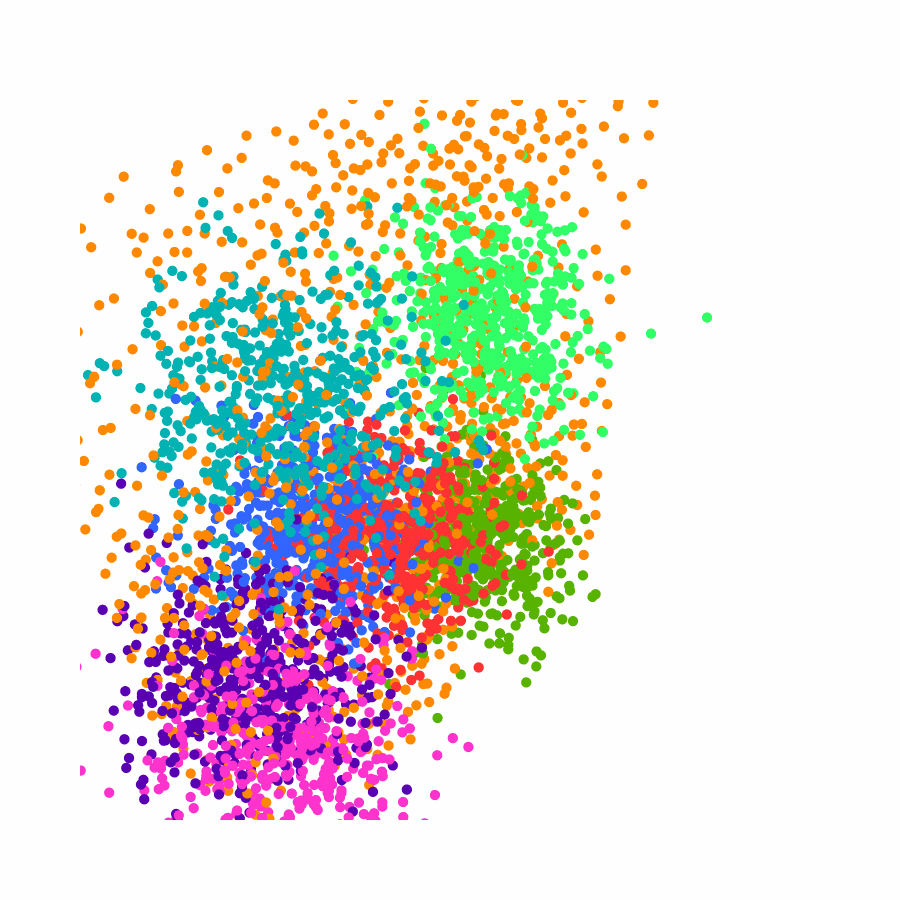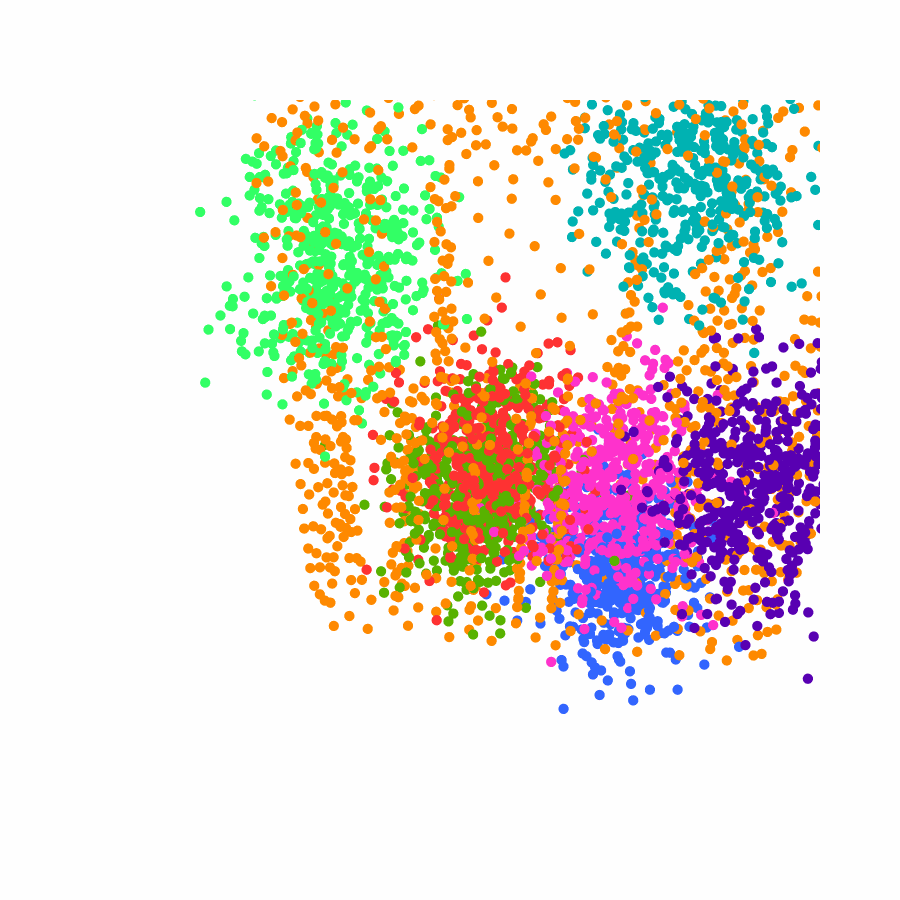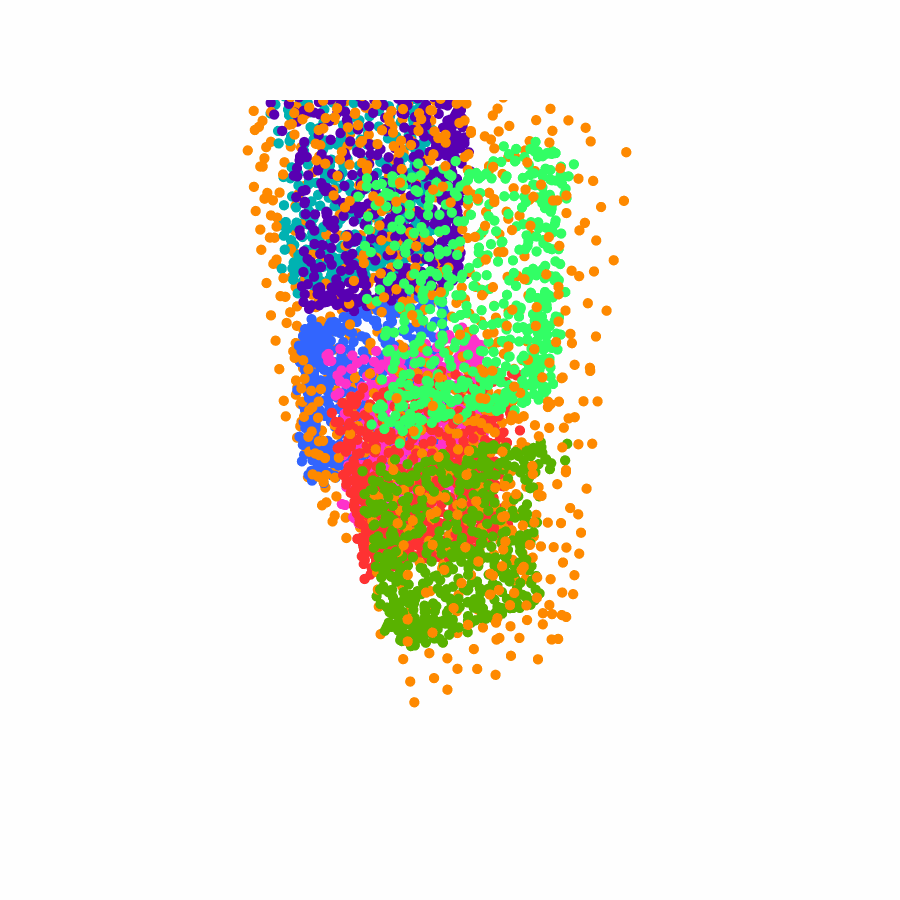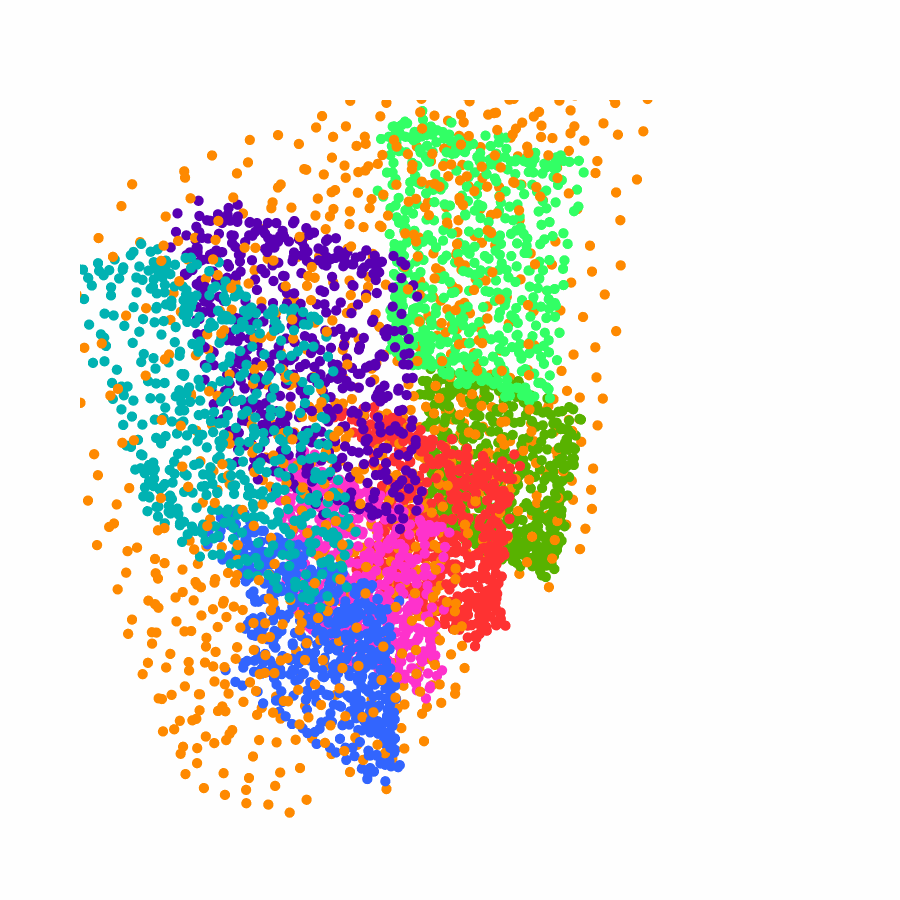
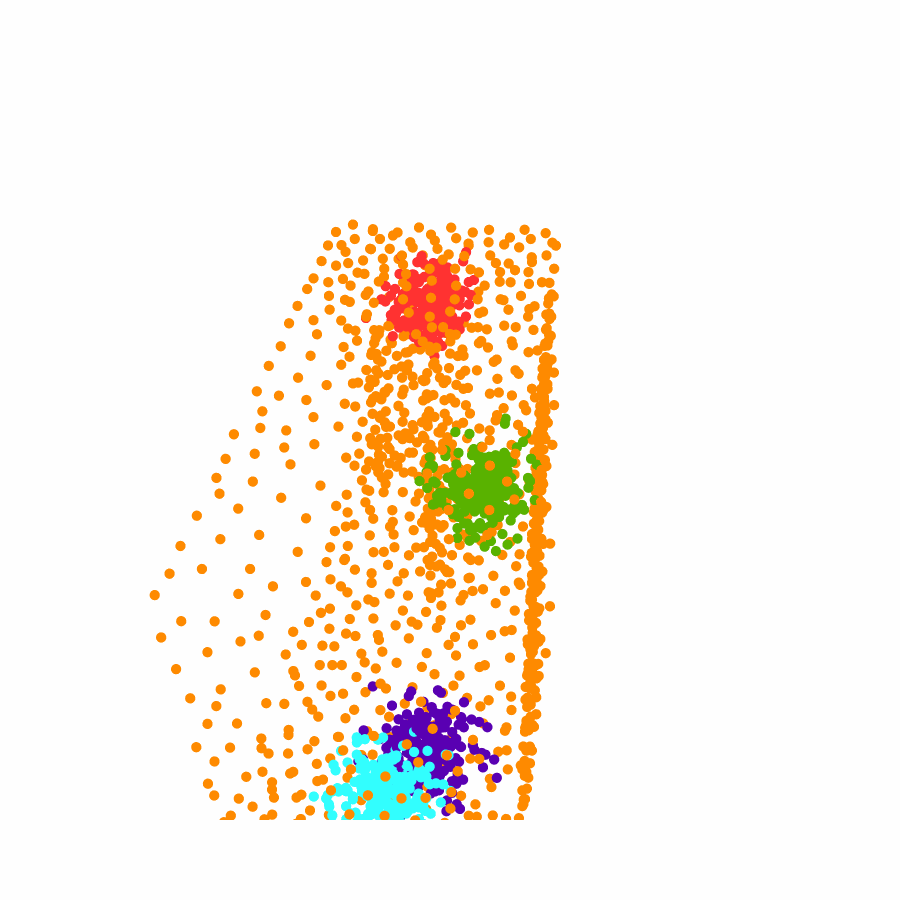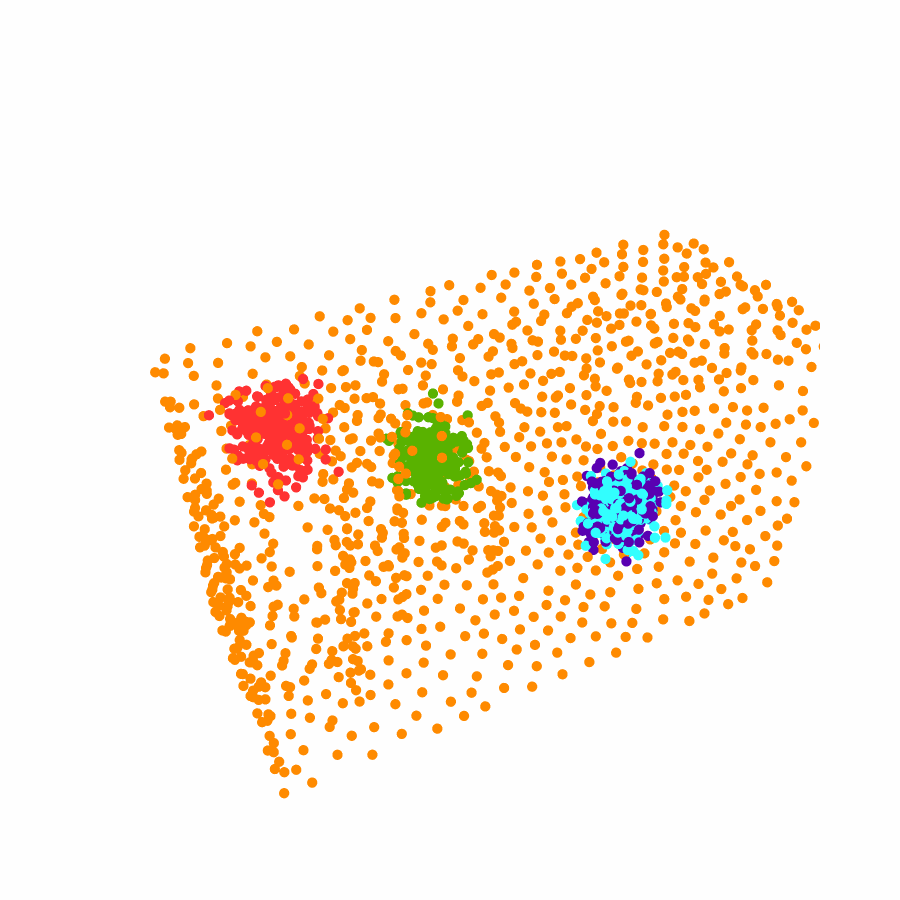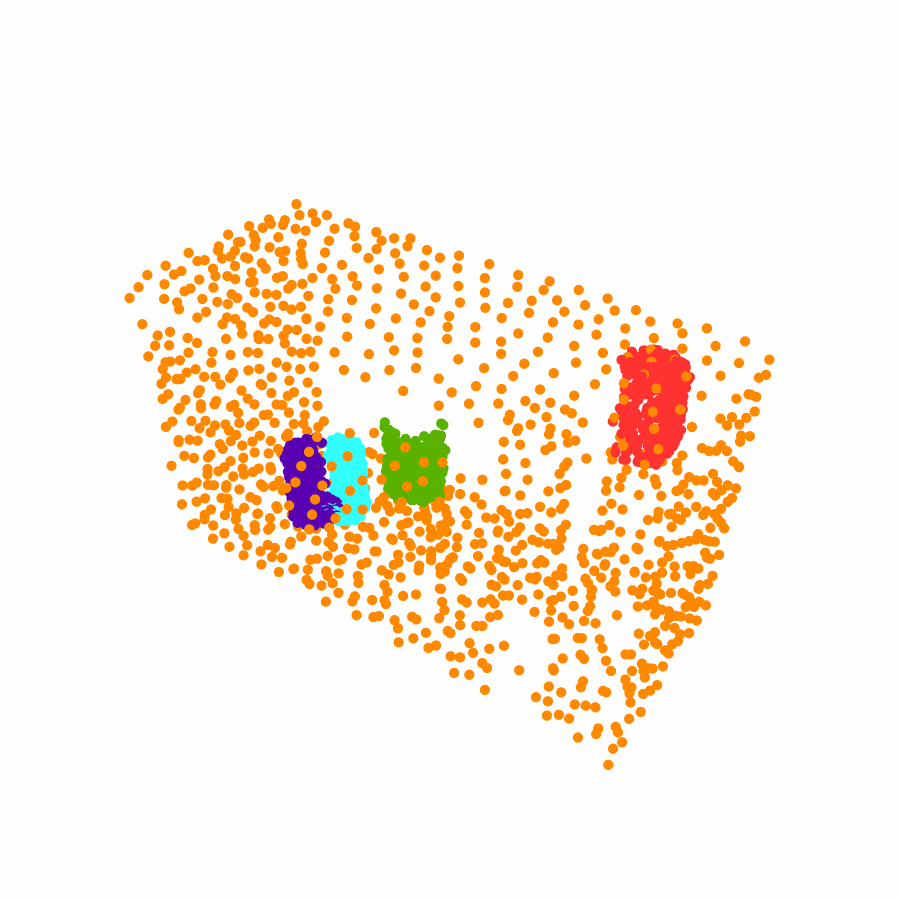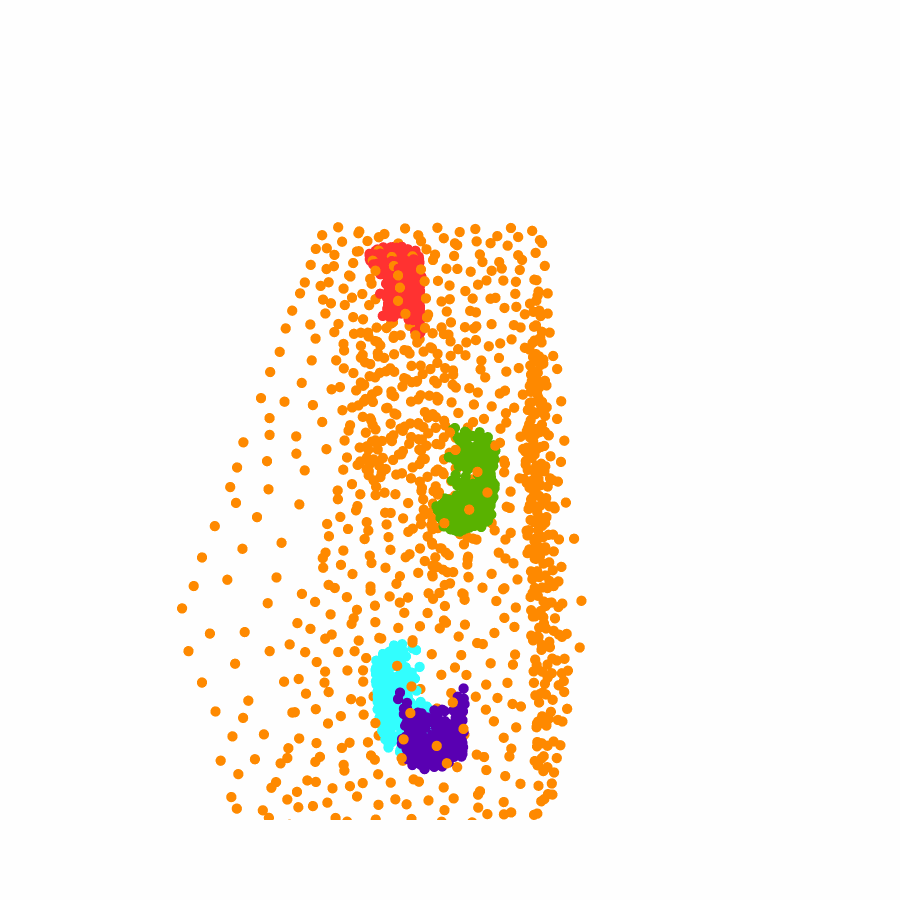
Specifically, we model global scene-level placements through a novel feed-forward Dense Gaussian Mixture Model (GMM) that yields a spatially dense prior over global placements; we then
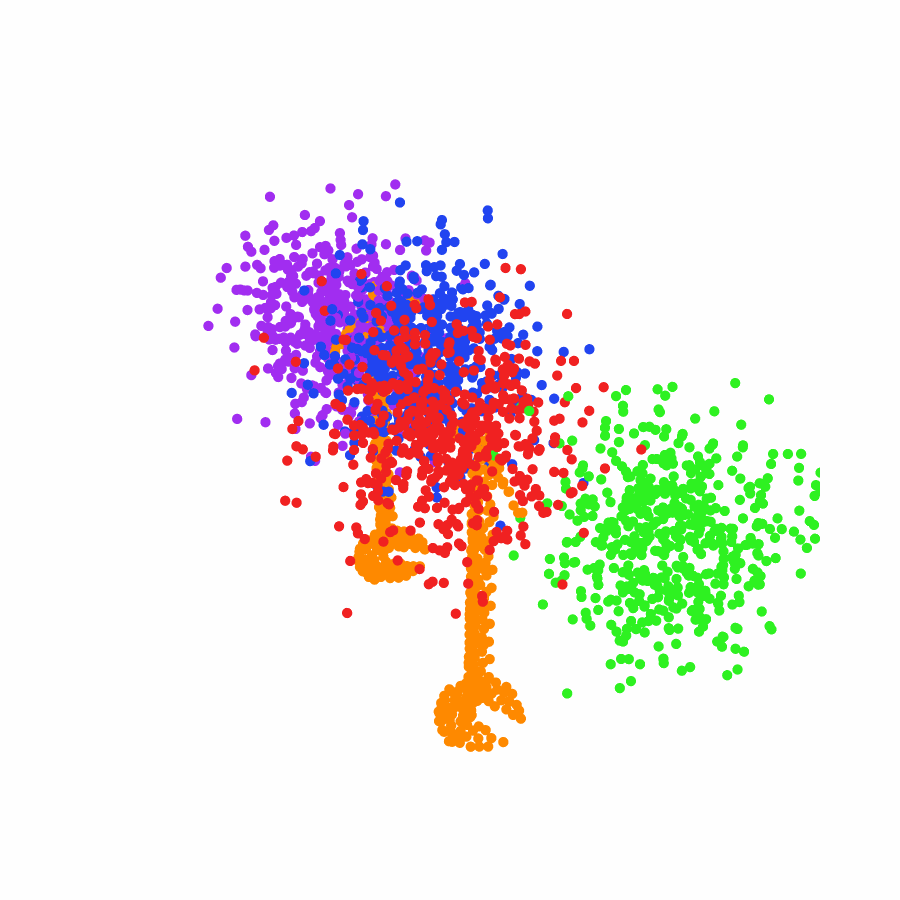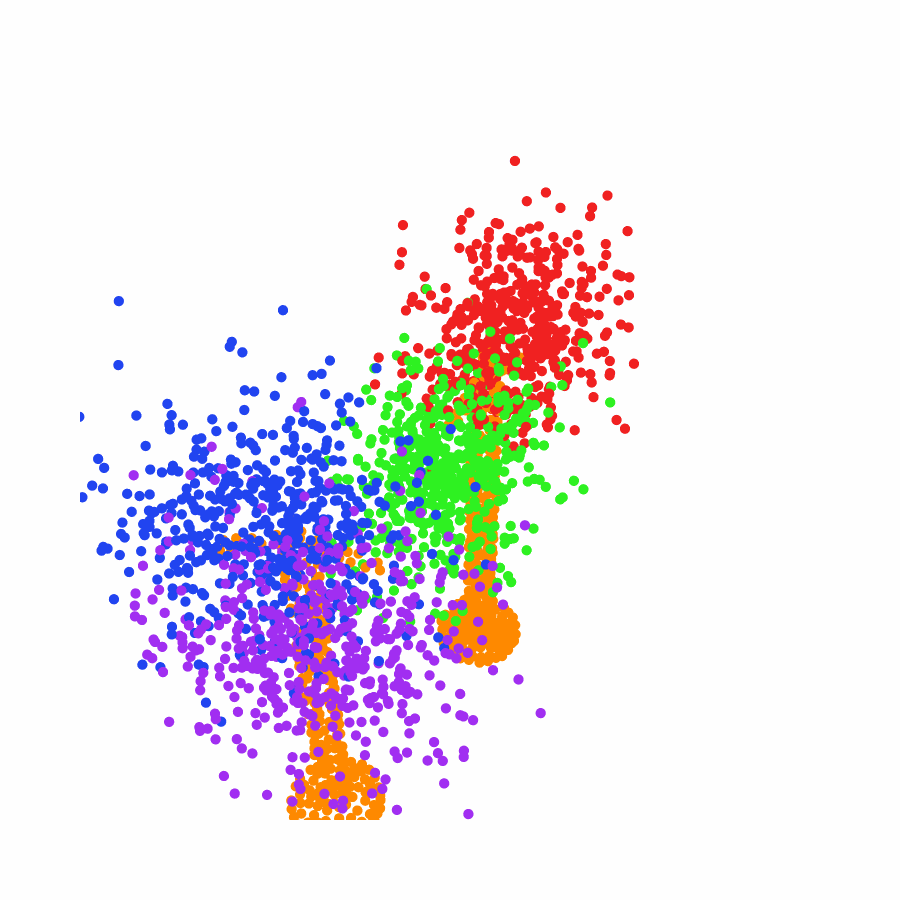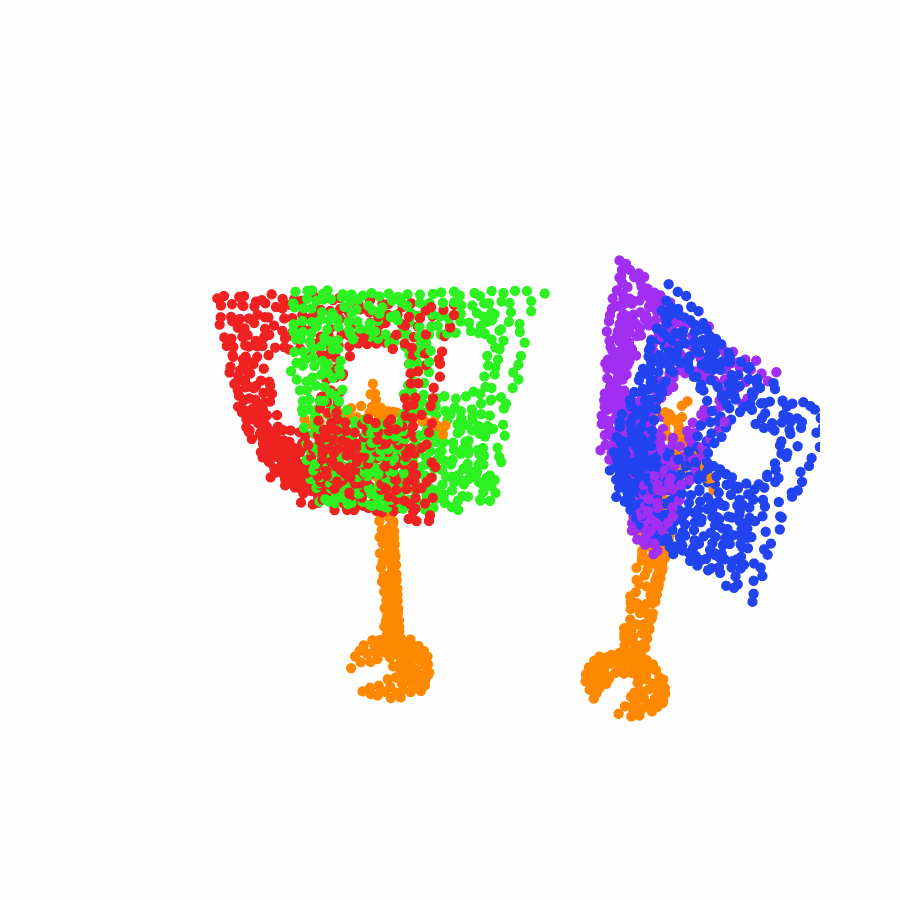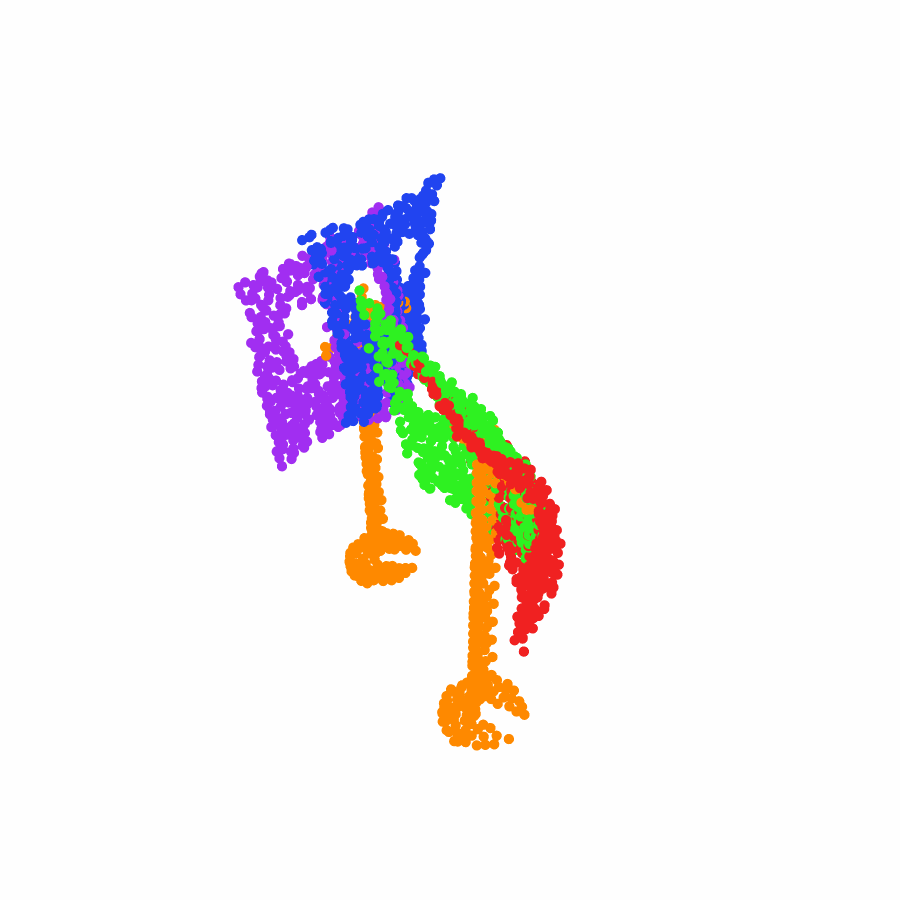
model the local object-level configuration through a novel disentangled point cloud diffusion module that separately diffuses the object geometry and the placement frame, enabling precise
local geometric reasoning. Interestingly, we demonstrate that our point cloud diffusion achieves substantially higher accuracy compared to prior approaches based on SE(3) diffusion, even
in the context of rigid object placement. We validate our approach across a suite of challenging tasks in simulation and in the real-world on high-precision industrial insertion tasks.
Furthermore, we present results on a cloth-hanging task in simulation, indicating that our method can further relax assumptions on object rigidity.